|
|
case1和2有什么影响?假设auto_commit
好处
- 减少与mysql server的交互
- 减少SQL解析(如果statement则没区别)
- query cache打开时,只会invalidate cache一次,提高cache hit
坏处
- 可能变成一个大事务
batch insert的时候,batch不能太大
|
|
每条消息12345678QueueOffset针对普通消息,存的是consume log里的offset;如果事务消息,是事务状态表的offset+---------+-------+-----+---------+------+-------------+----------------+----------------+| MsgSize | Magic | CRC | QueueID | Flag | QueueOffset | PhysicalOffset | SysFlag(P/C/R) |+---------+-------+-----+---------+------+-------------+----------------+----------------++--------------+------------------+-----------+---------------+----+------+-------+------+| ProducedTime | ProduderHostPort | StoreTime | StoreHostPort | .. | Body | Topic | Prop |+--------------+------------------+-----------+---------------+----+------+-------+------+
每次append commit log,会同步调用dispatch分发到consume queue和索引服务1234567new DispatchRequest(topic, queueId, result.getWroteOffset(), result.getWroteBytes(), tagsCode, msg.getStoreTimestamp(), result.getLogicsOffset(), msg.getKeys(), // Transaction msg.getSysFlag(), msg.getPreparedTransactionOffset());
仅仅是逻辑概念,可以通过它来参与producer balance,类似一致哈希里的虚拟节点
每台broker上的commitlog被本机所有的queue共享,不做任何区分
|
|
消息的局部顺序由producer client保证
|
|
读一条消息,先读consume queue(类似mysql的secondary index),再读commit log(clustered index)
没有采用sendfile,而是通过mmap:因为random read
|
|
虽然消费时,consume queue是顺序的,但接下来的commit log几乎都是random read,此外
如何优化压缩?光靠pagecache+readahead是远远不够的
|
|
|
|
保存在broker,默认1m扫一次
|
|
对于未决事务,根据随机向Producer Group里的一台发请求CHECK_TRANSACTION_STATE
Producer Group根据redolog(mmap)定位状态
Producer Group信息存放在namesvr
粒度只控制在Broker,而kafka是在partition上
consumer有需求回放/快进消息,目前kateway具有该功能:
用户在web console上把offset设置到指定位置
但由于机器里kateway正在消费源源不断的消息,checkpoint会overwrite这个指定的offset
这就要求用户先关闭消费进程,然后web console上操作,再启动消费进程: not user friendly
在不影响性能前提下,对其进行改进
|
|
大部分是基于Selinger的论文,动态规划算法,把这个问题拆解成3个子问题
Gray论文
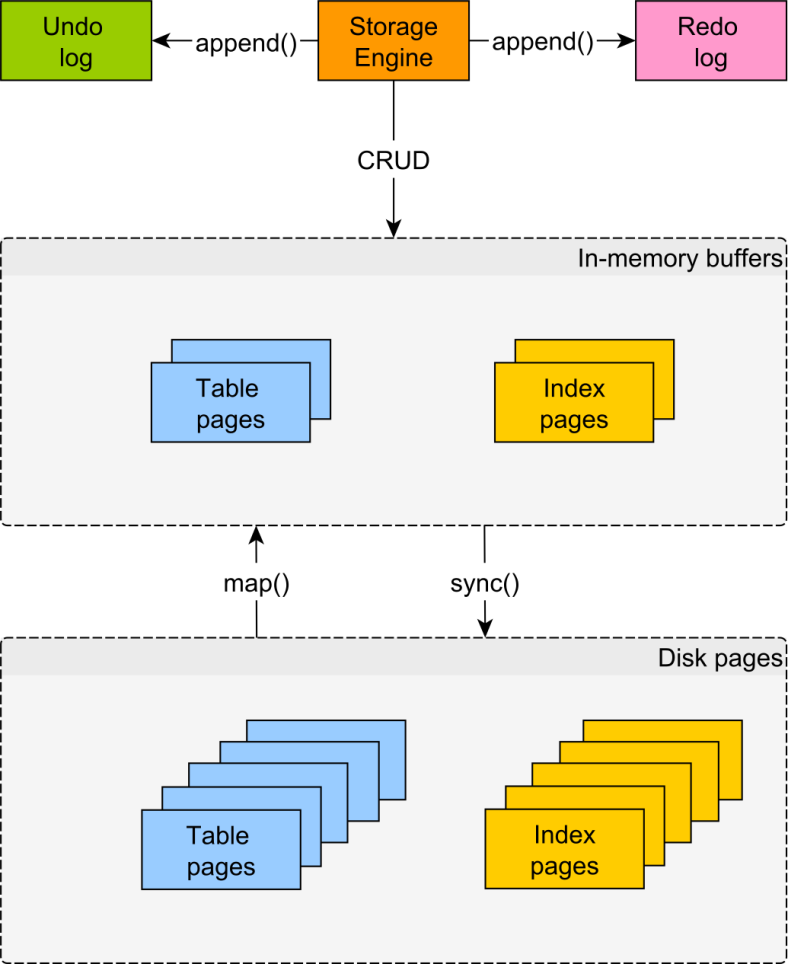
IBM的ARIES算法(1992),Algorithm for Recovery and Isolation Exploiting Semantics
ARIES can only update the data in-place after the log reaches storage
确保在恢复时,已经commit的事务要redo,未commit的事务要undo
redo log是物理的,undo log是逻辑的
No Force, Steal
ARIES为each page保存LSN,disk page是数据管理和恢复的基本单位,page write是原子的
ARIES crash recovery分成3步
ARIES数据结构
Example123456789101112131415161718192021222324252627282930After a crash, we find the following log:0 BEGIN CHECKPOINT5 END CHECKPOINT (EMPTY XACT TABLE AND DPT)10 T1: UPDATE P1 (OLD: YYY NEW: ZZZ)15 T1: UPDATE P2 (OLD: WWW NEW: XXX)20 T2: UPDATE P3 (OLD: UUU NEW: VVV)25 T1: COMMIT30 T2: UPDATE P1 (OLD: ZZZ NEW: TTT)Analysis phase:Scan forward through the log starting at LSN 0.LSN 5: Initialize XACT table and DPT to empty.LSN 10: Add (T1, LSN 10) to XACT table. Add (P1, LSN 10) to DPT.LSN 15: Set LastLSN=15 for T1 in XACT table. Add (P2, LSN 15) to DPT.LSN 20: Add (T2, LSN 20) to XACT table. Add (P3, LSN 20) to DPT.LSN 25: Change T1 status to "Commit" in XACT tableLSN 30: Set LastLSN=30 for T2 in XACT table.Redo phase:Scan forward through the log starting at LSN 10.LSN 10: Read page P1, check PageLSN stored in the page. If PageLSN<10, redo LSN 10 (set value to ZZZ) and set the page's PageLSN=10.LSN 15: Read page P2, check PageLSN stored in the page. If PageLSN<15, redo LSN 15 (set value to XXX) and set the page's PageLSN=15.LSN 20: Read page P3, check PageLSN stored in the page. If PageLSN<20, redo LSN 20 (set value to VVV) and set the page's PageLSN=20.LSN 30: Read page P1 if it has been flushed, check PageLSN stored in the page. It will be 10. Redo LSN 30 (set value to TTT) and set the page's PageLSN=30.Undo phase:T2 must be undone. Put LSN 30 in ToUndo.Write Abort record to log for T2LSN 30: Undo LSN 30 - write a CLR for P1 with "set P1=ZZZ" and undonextLSN=20. Write ZZZ into P1. Put LSN 20 in ToUndo.LSN 20: Undo LSN 20 - write a CLR for P3 with "set P3=UUU" and undonextLSN=NULL. Write UUU into P3.
ARIES是为传统硬盘设计的,顺序写,但成本也明显:修改1B,需要redo 1B+undo 1B+page 1B=3B
what if in-place update with SSD?
mid-1970s 2PC 一票否决
https://blog.acolyer.org/2016/01/08/aries/
http://cseweb.ucsd.edu/~swanson/papers/SOSP2013-MARS.pdf
https://www.cs.berkeley.edu/~brewer/cs262/Aries.pdf
WebRTC提供了direct data and media stream transfer between two browsers without external server involved: P2P
浏览器上点击“Screen share”按钮后
|
|
通过WebRTC实现的是只读的屏幕分享,receiver不能控制sender屏幕
实现123456789101112131415161718192021222324252627<body> <p><input type="button" id="share" value="Screen share" /></p> <p><video id="video" autoplay /></p></body><script>navigator.getUserMedia = navigator.webkitGetUserMedia || navigator.getUserMedia;$('#share').click(function() { navigator.getUserMedia({ audio: false , video: { mandatory: { chromeMediaSource: 'screen' , maxWidth: 1280 , maxHeight: 720 } , optional: [ ] } }, function(stream) { // we've got media stream // so the received stream can be transmitted via WebRTC the same way as web camera and easily played in <video> component on the other side document.getElementById('video').src = window.URL.createObjectURL(stream); } , function() { alert('Error. Try in latest Chrome with Screen sharing enabled in about:flags.'); })})</script>
Remote Frame Buffer,支持X11, Windows, Mac
远程终端用户使用机器(比如显示器、键盘、鼠标)的叫做客户端,提供帧缓存变化的被称为服务器
pixel(x, y) => 像素数据编码
Raw, CopyRect, RRE, Hextile, TRLE, ZRLE
最重要的显示消息,表示client要server传回哪些区域的图像
|
|
client端的键盘动作
client端的鼠标动作
http://guacamole.incubator.apache.org/
https://github.com/novnc/noVNC
http://www.tuicool.com/articles/Rzqumu
https://github.com/macton/hterm
chrome://flags/#enable-usermedia-screen-capture
|
|
|
|
主流SSD,例如Samsung 960 Pro,可以提供440K/s random read
with block size=4KB
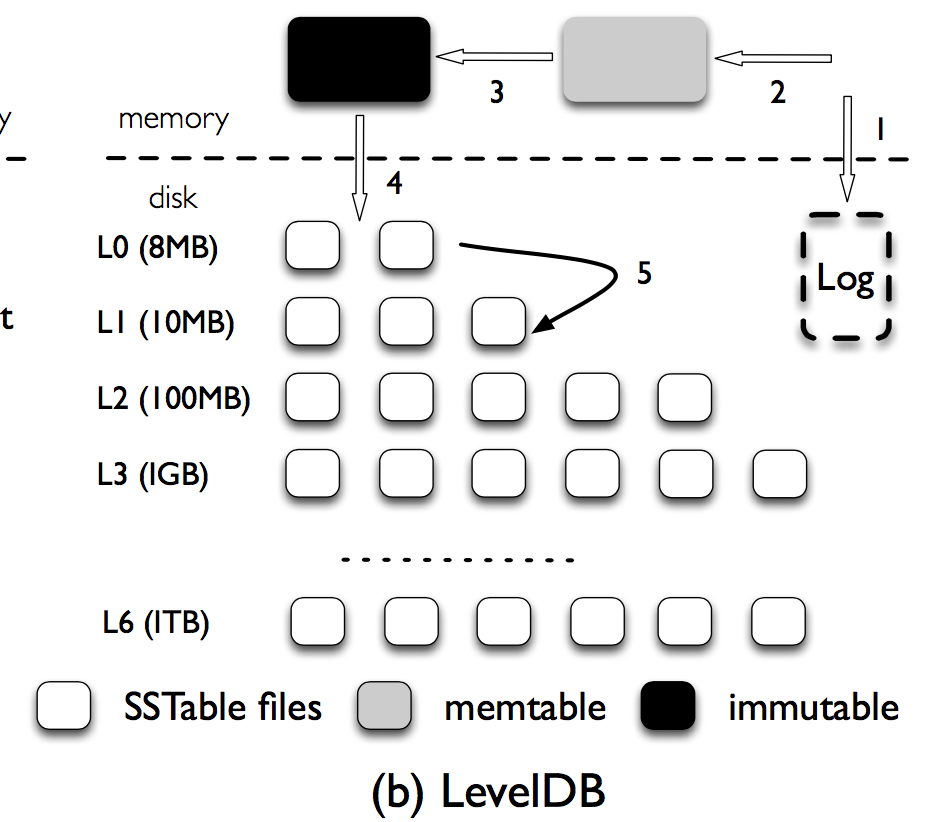
LSM是为传统硬盘设计的,在SSD下,可以做优化,不必过分担心随机读
LSM-Tree的主要成本都在compaction(merge sort),造成IO放大(50倍)
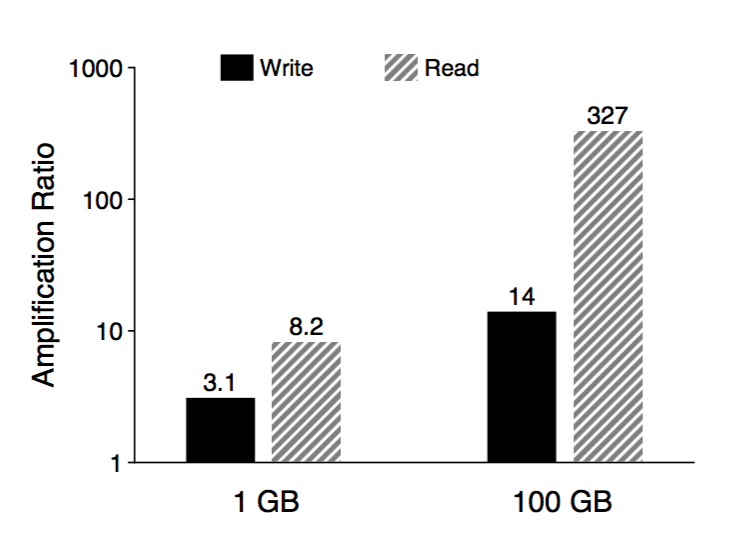
要优化compaction,可以把LSM Tree变小,RocksDB是通过压缩实现的
在SSD下,可以考虑把key和value分离,在LSM Tree里只保存sorted key和pointer(value),value直接保存在WAL里
key: 16B
pointer(value): 16B
2M个k/v,需要64MB
2B个k/v,需要64GB
https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf