Basics
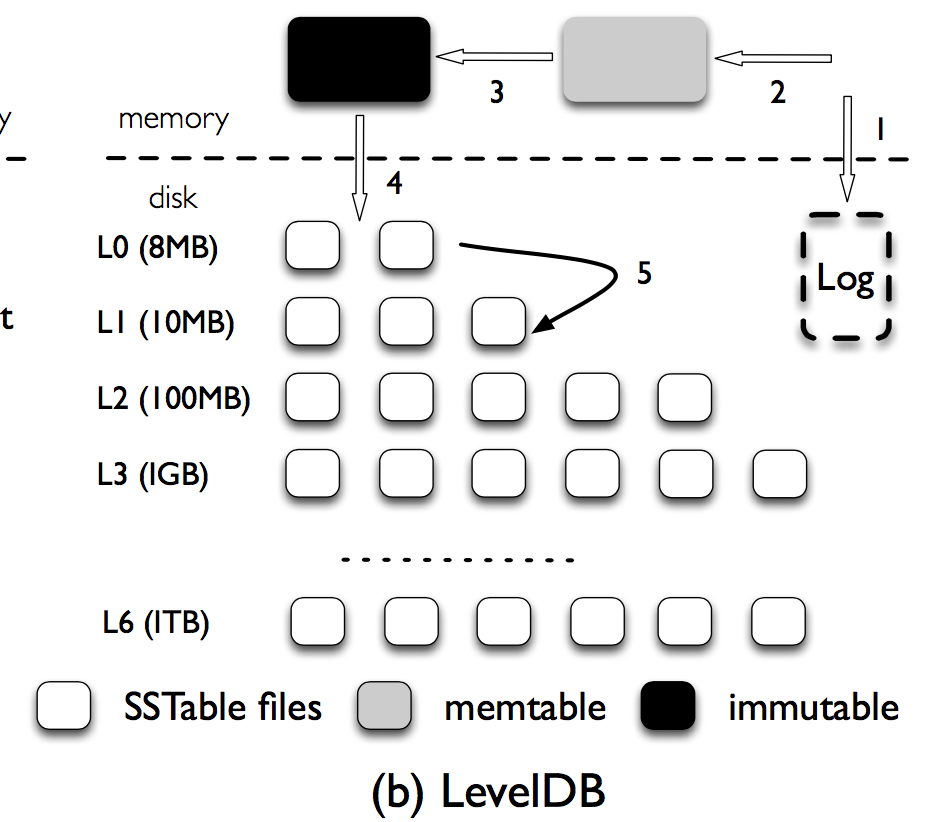
- (immutable)memtable: sorted skiplist
- SSTable: sorted string table
- L0里的SSTable们,key可能会overlap,因为他们是直接从immutable memtable刷出来的
SSTable file
|
|
Get(key)
|
|
SSD
主流SSD,例如Samsung 960 Pro,可以提供440K/s random read
with block size=4KB
LSM是为传统硬盘设计的,在SSD下,可以做优化,不必过分担心随机读
优化
LSM-Tree的主要成本都在compaction(merge sort),造成IO放大(50倍)
- 读很多文件到内存
- 排序
- 再写回到磁盘
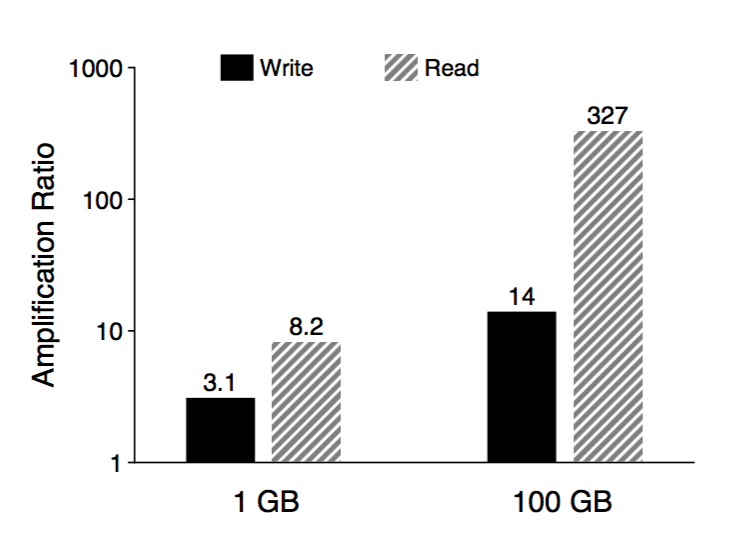
要优化compaction,可以把LSM Tree变小,RocksDB是通过压缩实现的
在SSD下,可以考虑把key和value分离,在LSM Tree里只保存sorted key和pointer(value),value直接保存在WAL里
key: 16B
pointer(value): 16B
2M个k/v,需要64MB
2B个k/v,需要64GB
Reference
https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf