TimescaleDB solves this through its heavy utilization of time-space partitioning, even when running on a single machine. So all writes to recent time intervals are only to tables that remain in memory, and updating any secondary indexes is also fast as a result.
retention
删除数据时,不是delete by row,而是delete by chunk,把整个chunk(table)删除就快了
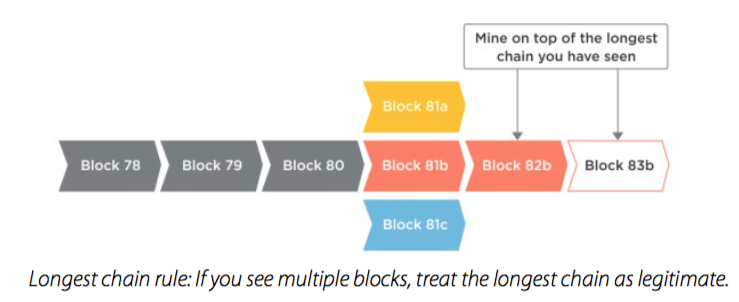
blockchain的所谓去中心化,实际上是建立一个少数服从多数的分布式权威网络,只要这个网络上节点足够多,就是可以信赖的 以前,用户trust银行;现在,用户trust majority nodes in blockchain network
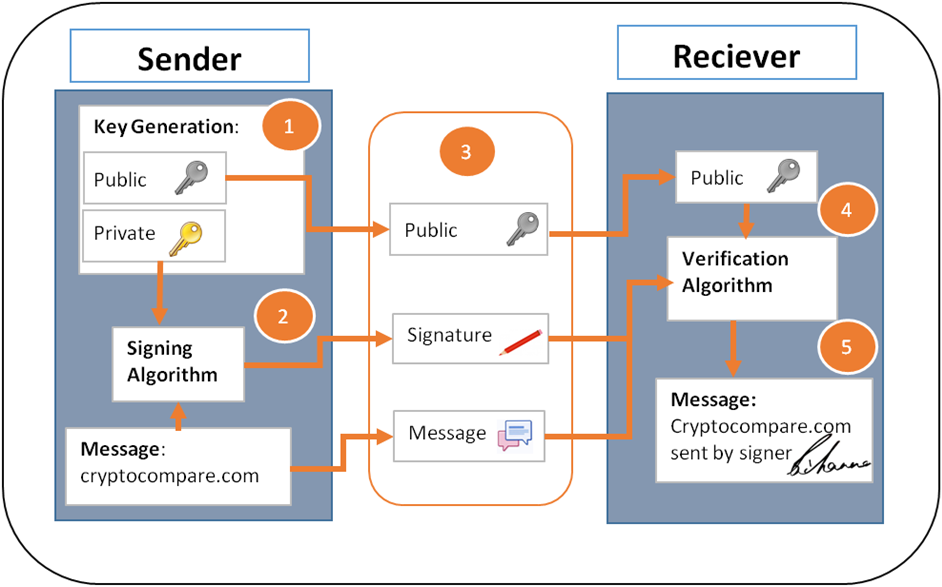
Bitcoin accounts: address public key: 1MKe24pNsLmFYk9mJd1dXHkKj9h5YhoEey private key: 5KkKR3VAjjPbHPzi3pWEHVQWrVa3C4fwD4PjR9wWgSV2D3kdmeM
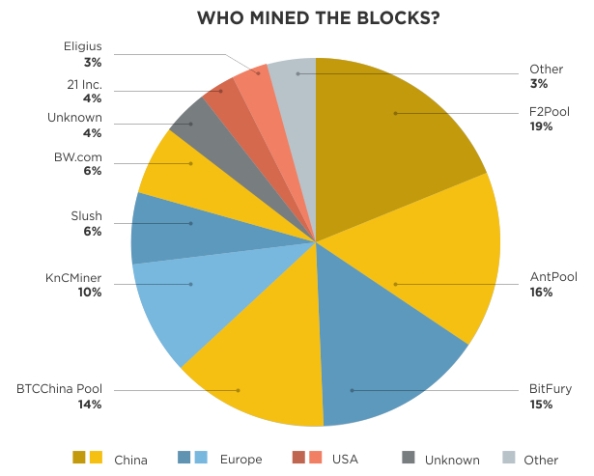
Currently, the top 10 mining pools consistently create about 90% of the blocks, and China-based pools create more than 60% of the blocks. 所以,虽然bitcoin设计上是去中心的,但目前的现状是实际上控制在少数人手里
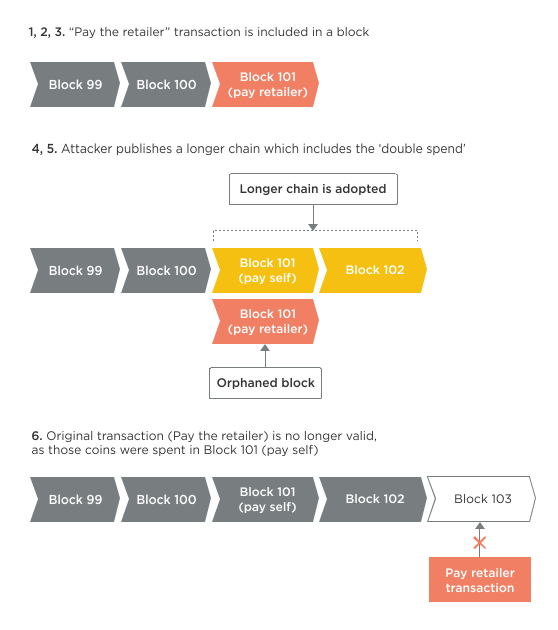
如果本来我想给A钱,却输入时写成了B的address,那么: Bitcoin transactions are not reversible. Sending to the wrong person cannot be undone.
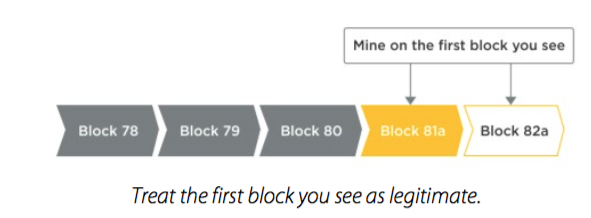
Block timestamp如果做假怎么办?
A timestamp is accepted as valid if it is greater than the median timestamp of previous 11 blocks, and less than the network-adjusted time + 2 hours. “Network-adjusted time” is the median of the timestamps returned by all nodes connected to you.
Whenever a node connects to another node, it gets a UTC timestamp from it, and stores its offset from node-local UTC. The network-adjusted time is then the node-local UTC plus the median offset from all connected nodes. Network time is never adjusted more than 70 minutes from local system time, however.
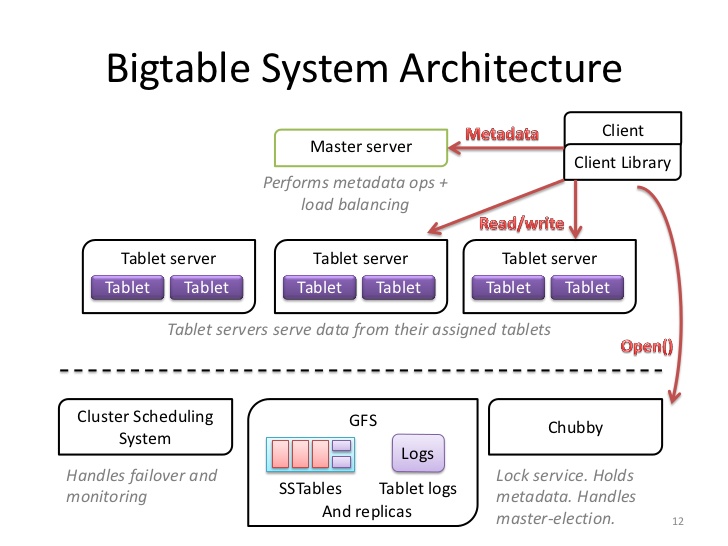
Colossus is specifically designed for BigTable, 没有GFS那么通用 In other words, it was built specifically for use with the new Caffeine search-indexing system, and though it may be used in some form with other Google services, it is not the sort of thing that is designed to span the entire Google infrastructure.
split and migration? 在没有crash情况下,只需要修改metadata和从sstable加载索引数据,效率很高
与GFS的对应
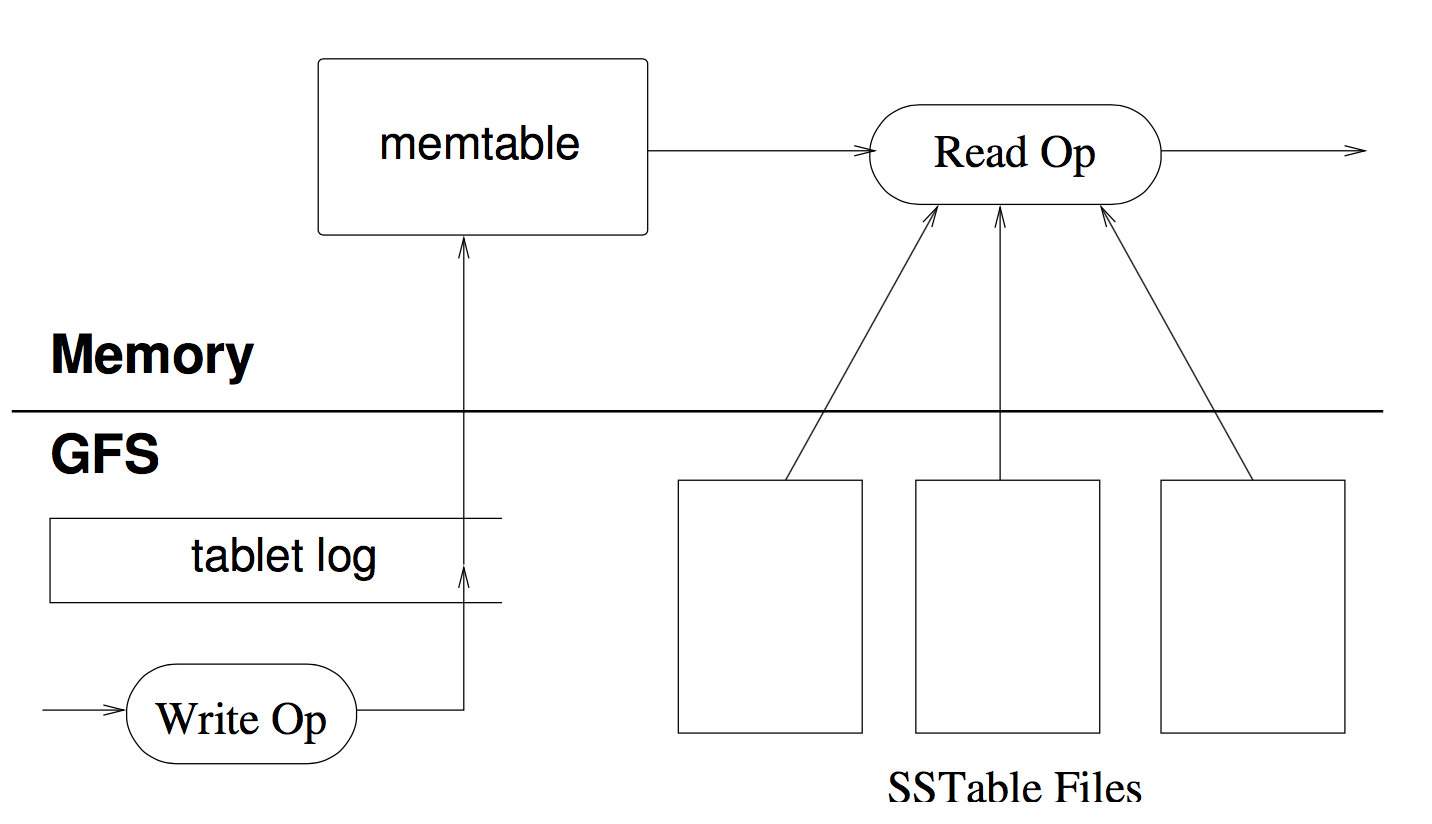
commit log 每台机器一个commit log文件,与GFS File一一对应
sstable HBase中Column Family的名称会被作为文件系统中的目录名称,每个CF存储成一个HDFS的HFile 据google工作过的人说:Column Families are stored in their own SSTable,应该是这样 sstable对应一个GFS File sstable block=64KB,它与GFS的block相同 sstable block为了压缩和索引(binary search),GFS block为了checksum
Highlights
redo log合并
一台机器一个redo log,而不是一个tablet一个redo log(每个机器有100-1000个tablet),否则GFS受不了 group commit
带来的问题:恢复时麻烦了 如果一天机器crash了,它上面的tablets会被master分配到很多其他的tabletserver上 例如,分配到了100台新tabletserver,他们都会read redo log and filter,这样redo log被读了100次 解决办法:利用类似MapReduce机制,在recovery之前先给redo log排序