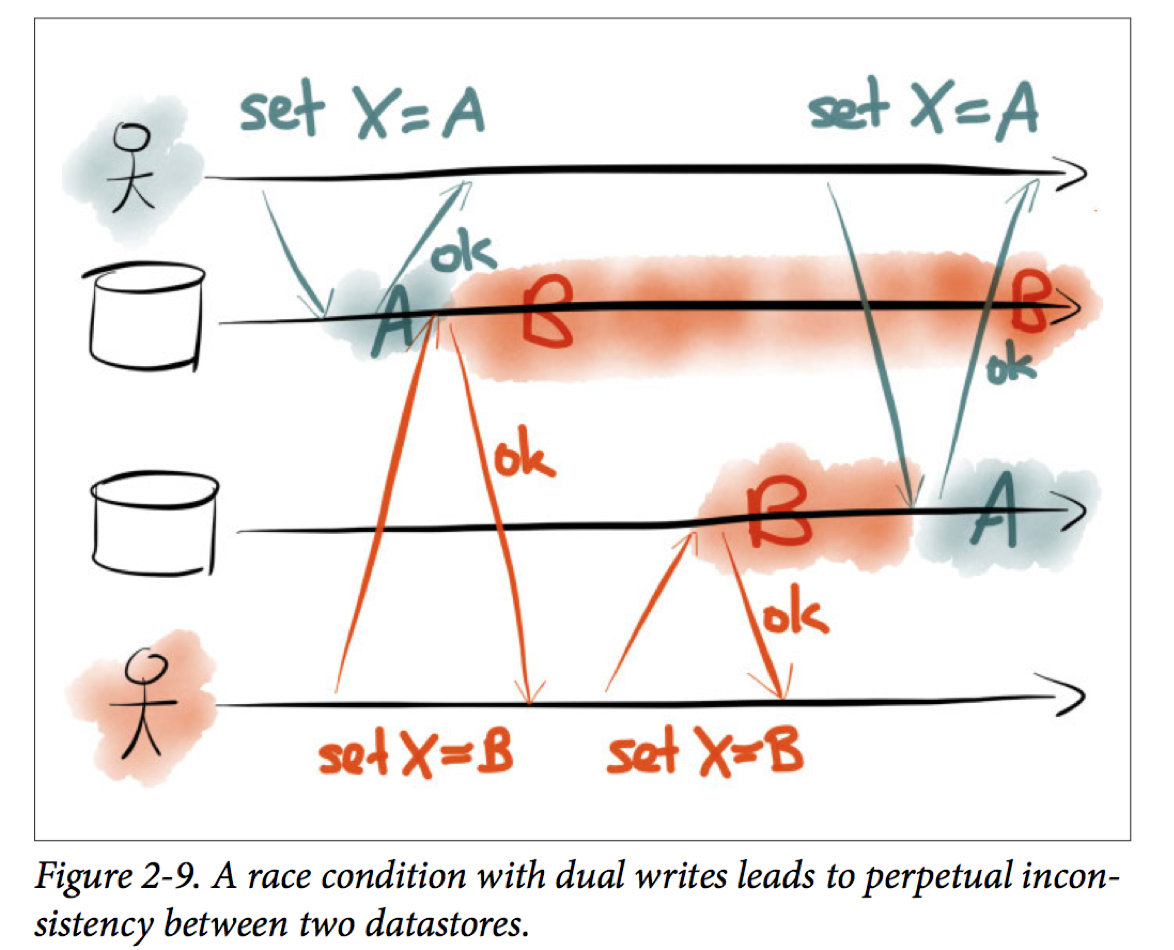
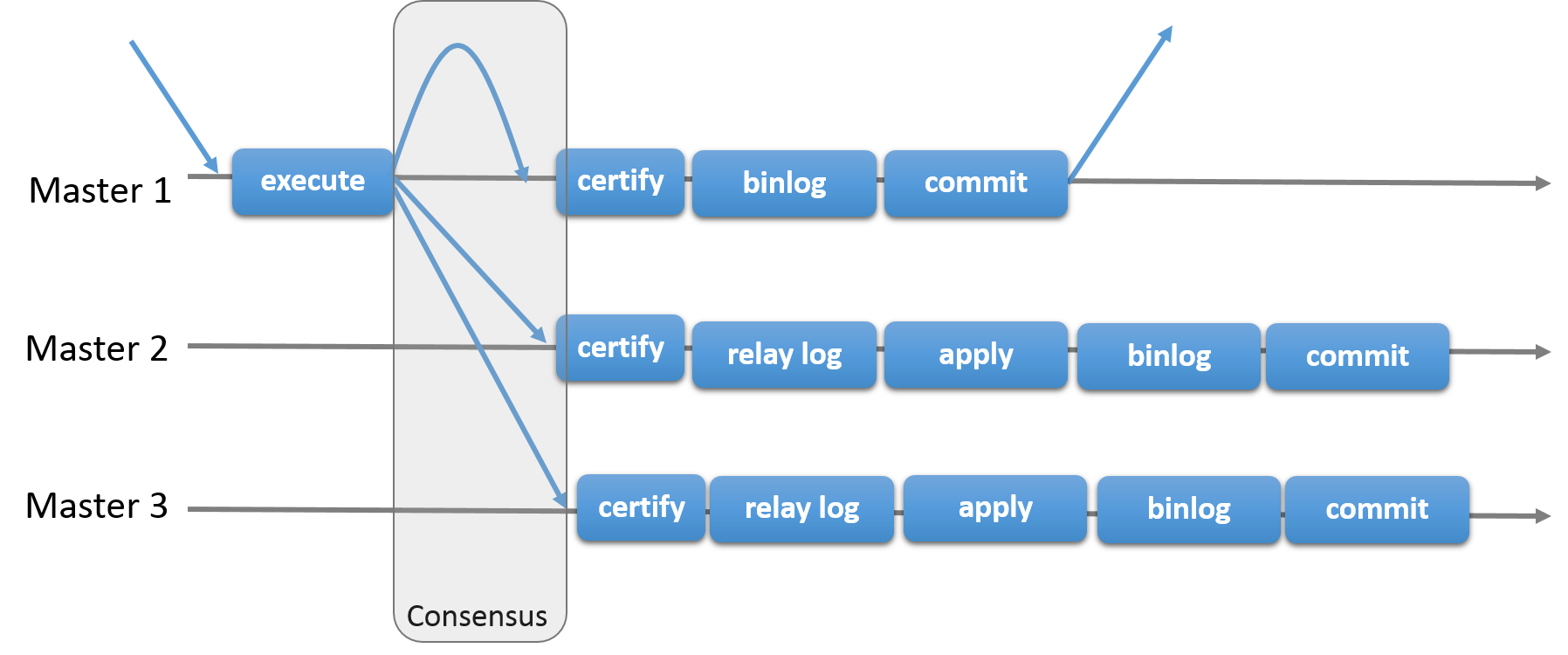
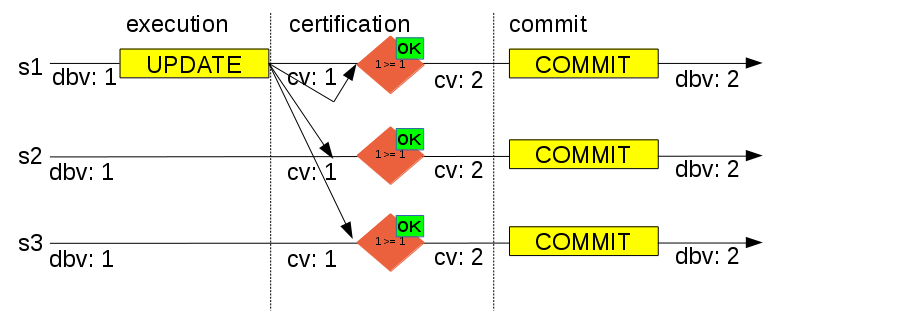
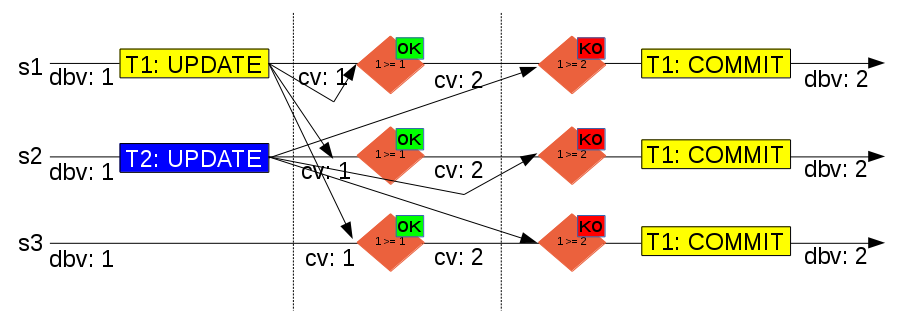
Basics Model File api without partial R/W
zab通过TCP+zxid实现事务的totally order
Implementation ZKDatabase1
2
3
4
5
6
7
// zk的内存数据库
class ZKDatabase {
DataTree dataTree
LinkedList<Proposal> committedLog
FileTxnSnapLog snapLog
ConcurrentHashMap<Long, Integer> sessionsWithTimeouts // {sessionID: timeout}
}
DataTree1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class DataTree {
ConcurrentHashMap<String, DataNode> nodes // {path: znode}, flat
ConcurrentHashMap<Long, HashSet<String>> ephemerals // {sessionID: [path, ]}
WatchManager dataWatches, childWatches
func createNode(path, data) {
parent = nodes.get(parentPath)
parent.Lock()
// check NodeExistsException
// set stat of the new znode and its parent
child = new DataNode(parent, data, stat) // the new znode
parent.addChild(child)
nodes.put(path, child)
if ephemeralOwner != nil {
ephemerals.get(ephemeralOwner).add(path)
}
parent.Unlock()
dataWatches.triggerWatch(path, NodeCreated)
childWatches.triggerWatch(parentPath, NodeChildrenChanged)
}
}
DataNode1
2
3
4
5
6
7
class DataNode {
DataNode parent
Set<String> children
StatPersisted stat
[]byte data
}
n(n-1)/2 conns 只允许id比较大的server发起主动连接:由于任意server在启动时都会主动向其他server发起连接,如果这样,任意两台server之间就拥有两条连接,这明显是没有必要的1
2
3
4
5
6
7
8
9
======= ======= ======= ======= ======= ========
sid 1 2 3 4 5
======= ======= ======= ======= ======= ========
1 <> < < < <
2 <> < < <
3 <> < <
4 <> <
5 <>
======= ======= ======= ======= ======= ========
成为 leader 的条件
选epoch最大的
epoch相等,选 zxid 最大的
epoch和zxid都相等,选择server id最大的
1
2
3
4
(newEpoch > curEpoch) ||
((newEpoch == curEpoch) &&
((newZxid > curZxid) ||
((newZxid == curZxid) && (newId > curId))))
何时选举 进入LOOKING状态
刚启动时
稳定运行中,任何的异常都会让本机进入LOOKING态1
2
3
catch (Exception e) {
setPeerState(LOOKING)
}
2PC 是个简化的2PC,因为不存在abort/rollback,只有commit
传统2PC里coordinator crash的硬伤,zk是怎么解决的?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
class LearnerHandler extends Thread {
queuedPackets = new LinkedBlockingQueue<QuorumPacket>()
}
class Leader {
func processAck(long zxid) {
Proposal p = outstandingProposals.get(zxid)
p.ackSet.add(1)
if p.ackSet.verifyQuorum() {
// 大多数返回ack了
outstandingProposals.remove(zxid)
commit(zxid) {
// 通知all followers
QuorumPacket qp = new QuorumPacket(Leader.COMMIT, zxid, null, null)
sendPacket(qp) // 异步
}
inform(p) {
// 通知all observers
}
}
}
func propose(req Request) {
Proposal p = new Proposal(req)
outstandingProposals.put(zxid, p)
sendPacket(p) {
for LearnerHandler f = range followers {
f.queuePacket(p)
}
}
}
}
class Follower {
func processPacket(QuorumPacket qp) {
switch qp.type {
case Leader.PROPOSAL:
// proposal只是记录txnlog,不改变database
FollowerZooKeeperServer.logRequest() {
pendingTxns.add(req)
txnLog.append(req)
}
case Leader.COMMIT:
FollowerZooKeeperServer.commit(qp.zxid) {
commitProcessor.commit(pendingTxns.remove()) {
committedRequests.add(req) {
FinalRequestProcessor.processRequest(req) {
ZooKeeperServer.processTxn -> ZKDatabase().processTxn
根据req.type来创建response,并发送
}
}
}
}
}
}
}
Constraints Many ZooKeeper write requests are conditional in nature:
a znode can only be deleted if it does not have any children
a znode can be created with a name and a sequence number appended to it
a change to data will only be applied if it is at an expected version
Quorum 1
2
3
4
5
6
7
8
9
10
11
12
13
14
func isQuorum(type) {
// zk的请求有2种 1. 事务请求 2. 只读请求
switch (type) {
case OpCode.exists, getACL, getChildren, getChildren2, getData:
// 本地执行,不需要proposal
return false
case OpCode.error, closeSession, create, createSession, delete, setACL, setData, check, multi:
return true
default:
return false
}
}
注意:session部分,也会走txn
multi 是原子操作,multi里的每个op都使用相同的zxid
Watch Watches are maintained locally at the ZooKeeper server to which the client is connected.
Watcher只会告诉客户端发生了什么类型的事件,而不会说明事件的具体内容
Watch的通知,由WatchManager完成,它先从内存里删除这个watcher,然后回调watcher.process
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class WatchManager {
HashMap<String, HashSet<Watcher>> watchTable
func triggerWatch(path, event) {
synchronized(this) {
watchers = watchTable.remove(path) // so one time trigger
}
// Watch机制本身是非常轻量级的,对服务器不会有多大开销:
// 它都是local zk server在内存中处理
// 但如果一个path的watcher很多,那么这个O(n)循环
for watcher = range watchers {
w.process(event)
}
}
}
func process(WatchedEvent event) {
h = new ReplyHeader(-1, -1L, 0)
sendResponse(h, event) // if IOException, close the client conn
// sock.write(非阻塞) async write
// sendResponse对同一个client是串行的,顺序的
}
顺序 1
2
3
4
5
6
client.get(path, watch=true)
// 此时数据发生变化
zk保证的顺序:
client先拿到watch event,之后才能看到最新的数据
client如果watch很多时间,那么得到这些event的顺序与server端发生的顺序是完全一致的
watch的保持 zk client连接zk1, 并get with watch,突然zk1 crash,client连接到zk2,那么watch
watch的事件会丢吗 client2能获取到每次的set事件吗?1
2
client1不停地set(node, newValue)
client2 get with watch
不一定:因为是one time trigger
此外,zk与client的conn断开后,client会连接下一个zk,在此期间的事件lost
watch同一个znode多次,会收到几条event? 由于WatchManager的实现,相同类型的watch在一个path上被set多次,只会触发一次
1
2
create("/foo", EPHEMERAL_SEQUENTIAL)
exists("/foo", watcher) // 那么这个watch事件是永远不会trigger的,因为path不同,见WatchManager的实现
Client recvLoop里任意的错误,都会pick next server and authentication,进入新的循环
conn reset by peer
conn EOF
receive packet timeout
session expire
time
conn.recvTimeout = sessionTimeout * 2 / 3
ping interval = sessionTimeout / 3
例如,sessionTimeout=30s,那么client在等待20s还得不到response,就会try next server
Q/A client ping是如何保持住session的? client连接s1,定期ping,但s1 crash后client连接s2,为什么session能保持住?1
2
3
4
5
6
connect(s2)
send(ConnectRequest{LastZxidSeen, SessionID}) // SessionID是s1当时分配的
var r ConnectResponse = recv()
if r.SessionID == 0 {
// session expire
}
createSession会通过txn,因此client可以failover
session id zk session id assigned by server, global unique
1
2
3
4
5
6
func initializeNextSession(id=1) {
long nextSid = 0;
nextSid = (System.currentTimeMillis() << 24) >>> 8;
nextSid = nextSid | (id <<56);
return nextSid;
}
后面的session id就是这个种子基础上 increment by 1
Snapshot dataLogDir(txn log) and dataDir(snapshot) should be placed in 2 disk devices
when
System.getProperty(“zookeeper.snapCount”), 默认值100,000
takeSnapshot的时间在50,000 ~ 100,0000 之间的随机值
txn数量超过snapCount+随机数
roll txn log
创建一个线程,异步执行takeSnapshot。但前面的takeSnapshot线程未完成,则放弃
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Request si = getRequest()
if (zks.getZKDatabase().append(si)) { // txn log ok
logCount++; // logCount就是txn的数量
if (logCount > (snapCount / 2 + randRoll)) {
randRoll = r.nextInt(snapCount/2); // 为了防止集群内所有节点同时takeSnapshot加入随机
zks.getZKDatabase().rollLog(); // txn log will roll
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
} else {
snapInProcess = new Thread("Snapshot Thread") {
public void run() {
try {
zks.takeSnapshot();
} catch(Exception e) {
LOG.warn("Unexpected exception", e);
}
}
};
snapInProcess.start();
}
logCount = 0;
}
}
size 每个znode meta data至少76+path+data,如果1M znodes,平均size(path+data)=100,那么snapshot文件长度至少200MB
1
2
3
4
5
6
path(len4, path)
node
data(len4, data)
acl8
meta60
czxid8, mzxid8, ctime8, mtime8, version4, cversion4, aversion4, ephemeralOwner8, pzxid8
checksum Adler32
Edge cases leader election LOOKING后,把自己的zxid广播,是得到大多数同意就成为leader?
async commit [S1(leader), S2, S3]
leader在得到majority Ack(proposal)后,majority servers已经记录下了txnlog,leader发送Commit只是为了让servers
ZAB makes the guarantee that a proposal which has been logged by a quorum of followers will eventually be committed
换个角度看这个问题:
sync proposal [S1(leader), S2, S3, S4, S5]
不一定!
1
2
3
4
5
6
7
S1(leader), S2, S3, S4, S5
现在propose set(a)=b,S1确认了,但其他还没有确认,此时全部crash
然后启动S2-S5,等一会儿再启动S1,那么S2-S5他们的txid相同,会选出S5 leader
等S1启动时,它的txid是最大的,a=b可能会丢:
如果S1启动慢了200ms内,可能不会丢;否则,例如慢了1分钟,则丢了,S1变成follower后
会把该txid truncate: txnlog seek
FastLeaderElection.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
finalizeWait=200ms // 在得到majority确认后,但还没有得到全部确认,wait before make leader
sendNotifications()
for i.am.looking {
n = recvqueue.poll()
switch n.state {
case LOOKING:
compare my proposal with n and update my proposal
if every node agrees {
// got the leader!
return
}
if quorum agrees {
// Verify if there is any change in the proposed leader
for {
n = recvqueue.poll(200ms)
if n == nil {
break
}
}
}
case FOLLOWING, LEADING:
if leader is not me {
// confirm I have recv notification from leader
// stating that he is leader
}
}
}
References https://issues.apache.org/jira/browse/ZOOKEEPER-1813 https://issues.apache.org/jira/browse/ZOOKEEPER-417 https://issues.apache.org/jira/browse/ZOOKEEPER-1674 https://issues.apache.org/jira/browse/ZOOKEEPER-1642 http://blog.csdn.net/pwlazy/article/details/8080626