Trove
| Home | Archives |
|
https://github.com/skeema/skeema
统一控制dev/test/staging/prod等环境的scheme
|
|
与mysql在线alter table设计不同,它是higher level的,底层仍旧需要OSC支持:1alter-wrapper="/usr/local/bin/pt-online-schema-change --execute --alter {CLAUSES} D={SCHEMA},t={TABLE},h={HOST},P={PORT},u={USER},p={PASSWORDX}"
https://www.percona.com/live/17/sessions/automatic-mysql-schema-management-skeema
Cassandra 项目诞生于 Facebook,后来团队有人跳到 Amazon 做了另外一个 NoSQL 数据库 DynamoDB。
最开始由两个facebook的员工最开始开发出来的,其中一个还直接参与了Amazon的Dynamo的开发。
Dynamo论文发表于2007年,用于shopping cart
Cassandra在2008年被facebook开源,用于inbox search
Uber现在有全球最大的Cassandra data center
KVM核心人员用C++写的Cassandra(Java) clone,单机性能提高了10倍,主要原因是:
https://db-engines.com/en/ranking
https://github.com/scylladb/scylla
http://www.scylladb.com/
http://www.seastar-project.org/
https://www.reddit.com/r/programming/comments/3lzz56/scylladb_cassandra_rewritten_in_c_claims_to_be_up/
https://news.ycombinator.com/item?id=10262719
mini transation DSL
|
|
leases
|
|
watcher功能丰富
2M 256B keys123etcd2 10GBzk 2.4GBetcd3 0.8GB
调查来自47个国家的388个组织(公司)
26%受访者年销售额10亿美金以上
15%受访者每天处理10亿消息/天
43%受访者在公有云上使用kafka,其中60%是AWS
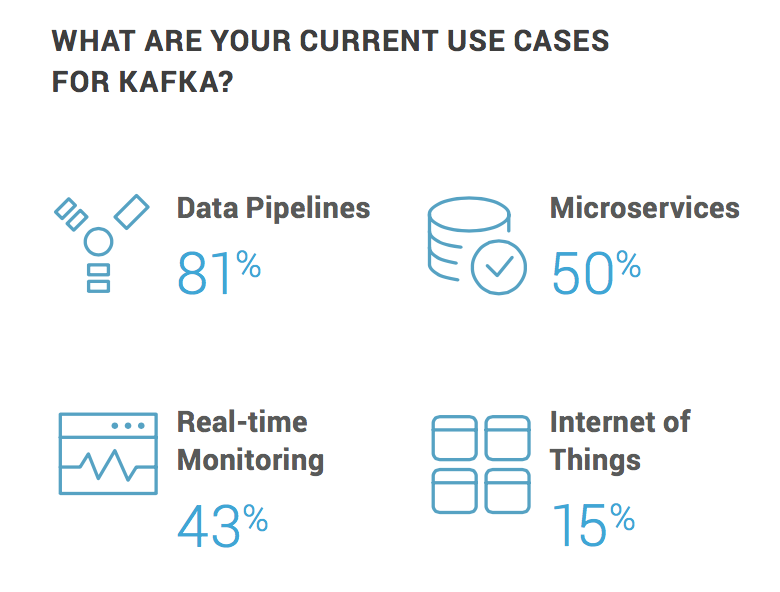
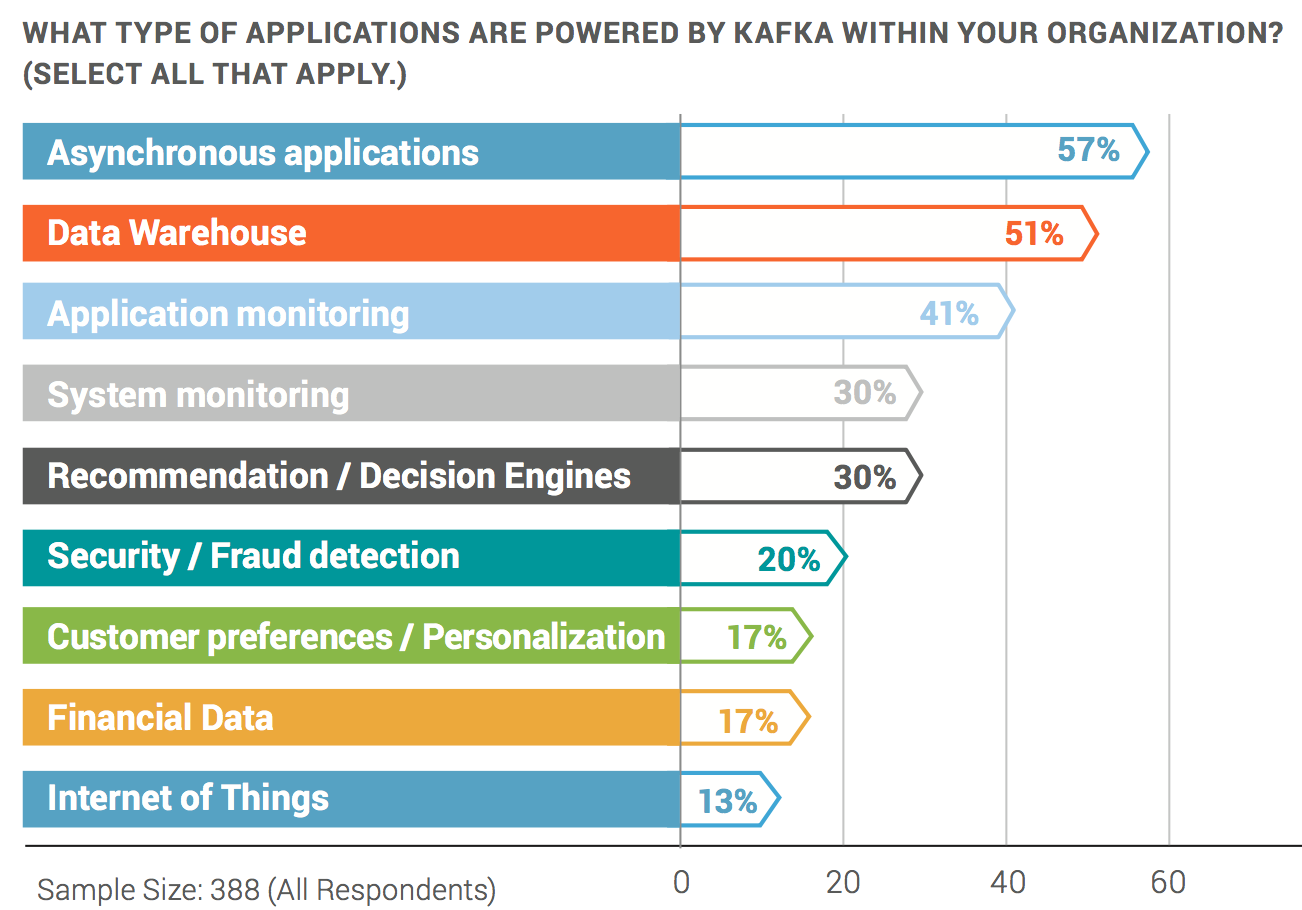
https://www.confluent.io/wp-content/uploads/2017-Apache-Kafka-Report.pdf
Chain of Responsibility
为了实现各种服务器的代码结构的高度统一,不同角色的server对应不同的processor chain
|
|
LeaderZooKeeperServer.java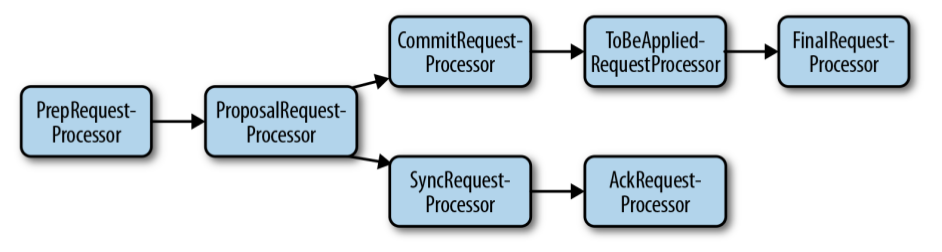
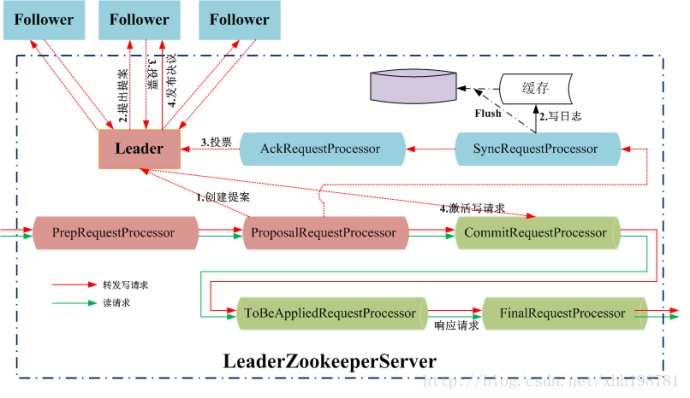
FollowerZooKeeperServer.java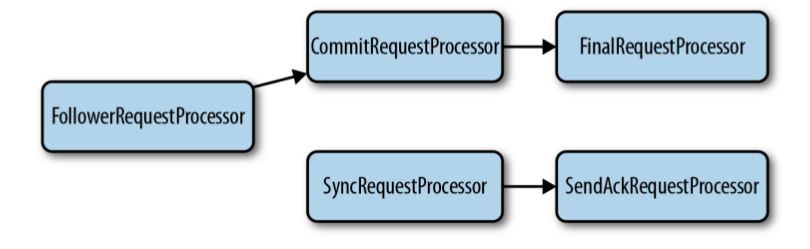
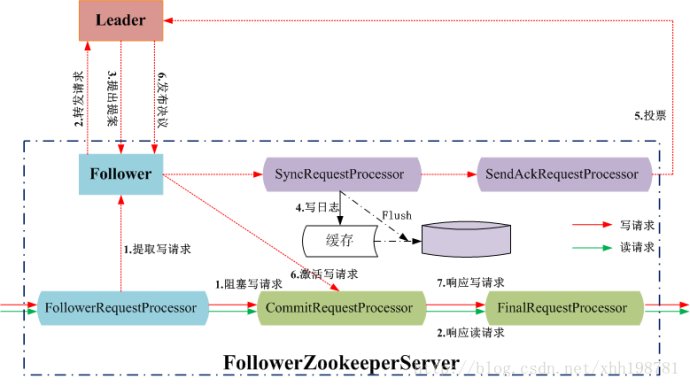
ZooKeeperServer.java1234567func processPacket() { submitRequest()}func submitRequest(req) { firstProcessor.processRequest(req)}
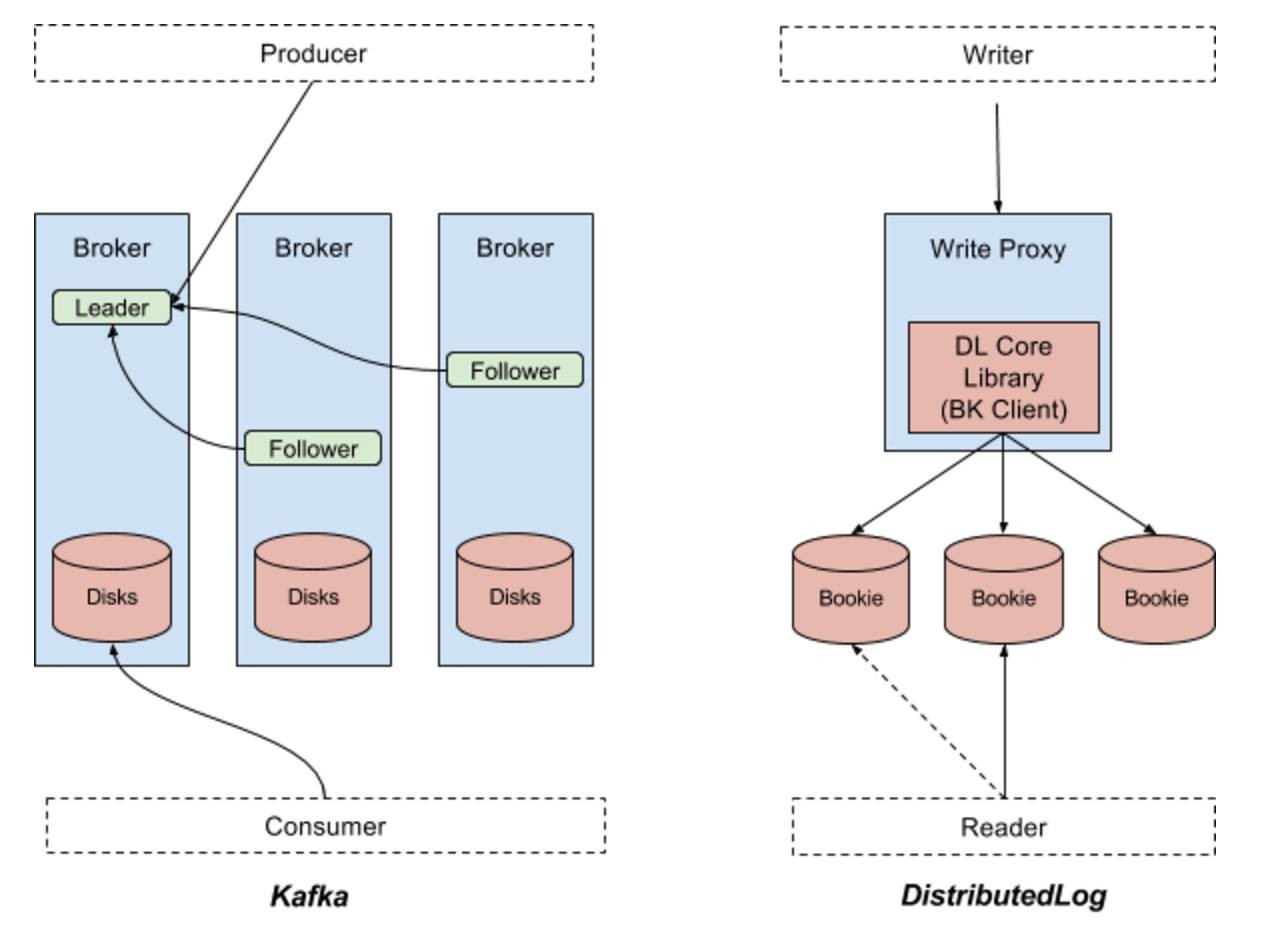
createLedger时,客户端决定如何placement(org.apache.bookkeeper.client.EnsemblePlacementPolicy),然后存放在zookeeper
例如,5个bookie,createLedger(3, 3, 2)
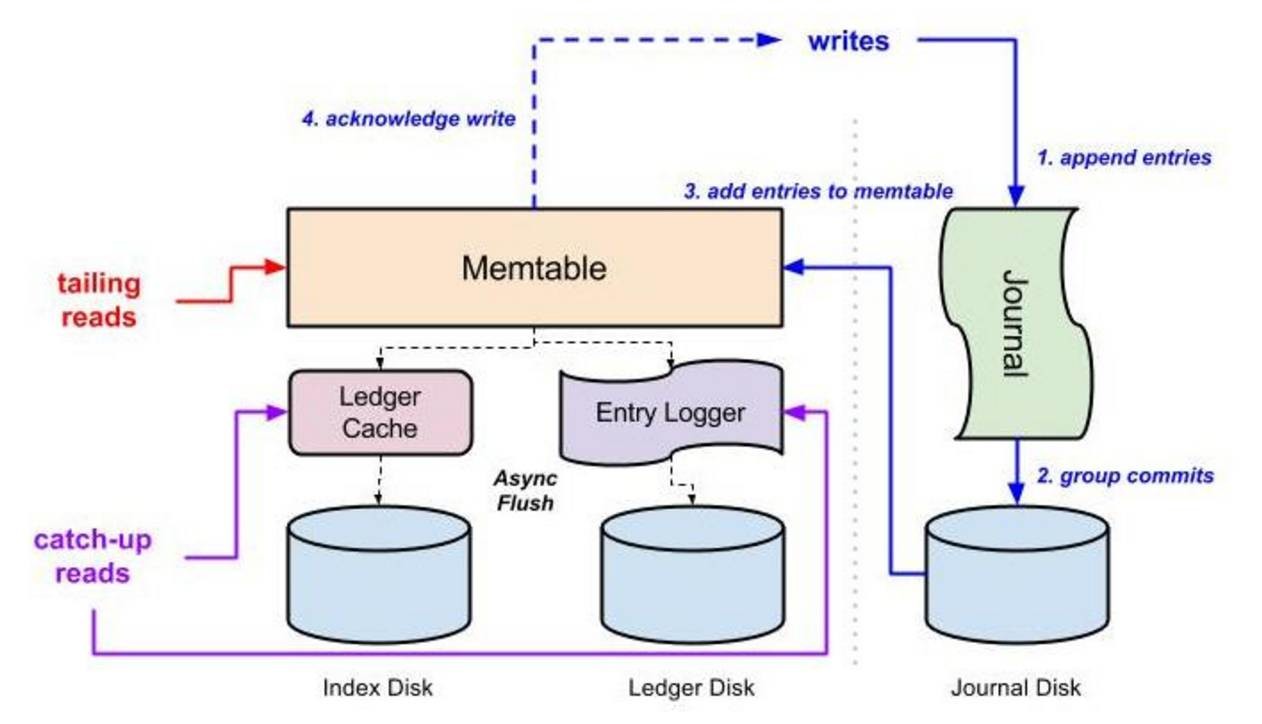
https://github.com/ivankelly/bookkeeper-tutorial
https://github.com/twitter/DistributedLog
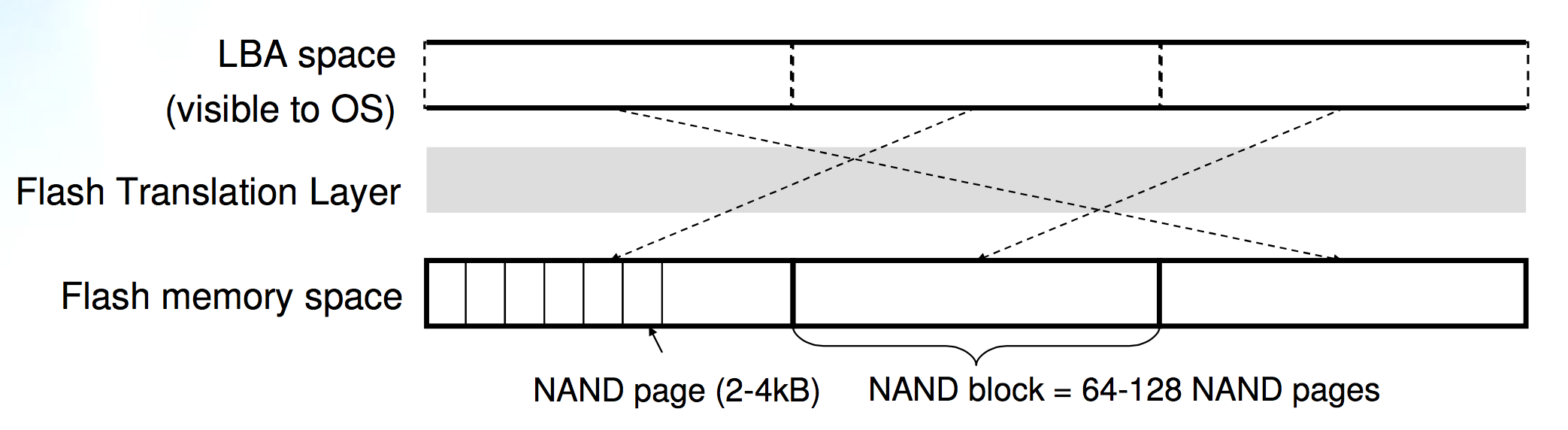
Physical unit of flash memory
物理特性
Cost: 17-32x more expensive per GB than disk
http://codecapsule.com/2014/02/12/coding-for-ssds-part-6-a-summary-what-every-programmer-should-know-about-solid-state-drives/
http://www.open-open.com/lib/view/open1423106687217.html
injecter负责write优化(WAL),让storage node负责read优化
与RocketMQ类似: CQRS
不同在于:storage node是通过pull mode replication机制实现,可以与injecter位于不同机器
而RocketMQ的commit log与consume log是在同一台broker上的
Producer通过forwarder连接到多个injecter上,injecter间通过gossip来负载均衡,load高的会通过与forwarder协商进行redirect distribution
scatter-gather