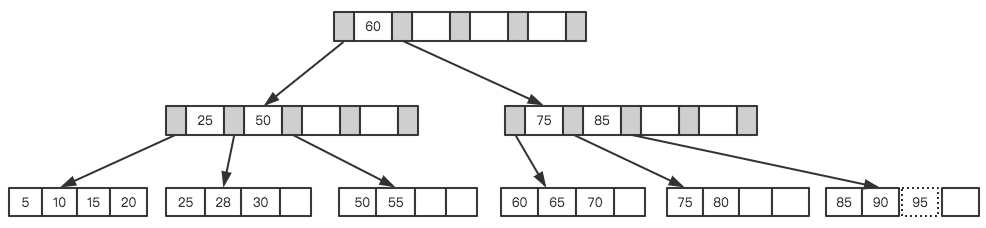
触发器的缺陷
- 如何监控
- 代码的版本控制
- test
- 部署
- 性能损耗
- 多租户
- 资源隔离
- 无法频繁发布,如何应付频繁的需求变更
触发器的缺陷
物化试图,可以理解为cache of query results, derived result
觉得用“异构表”可能更贴切
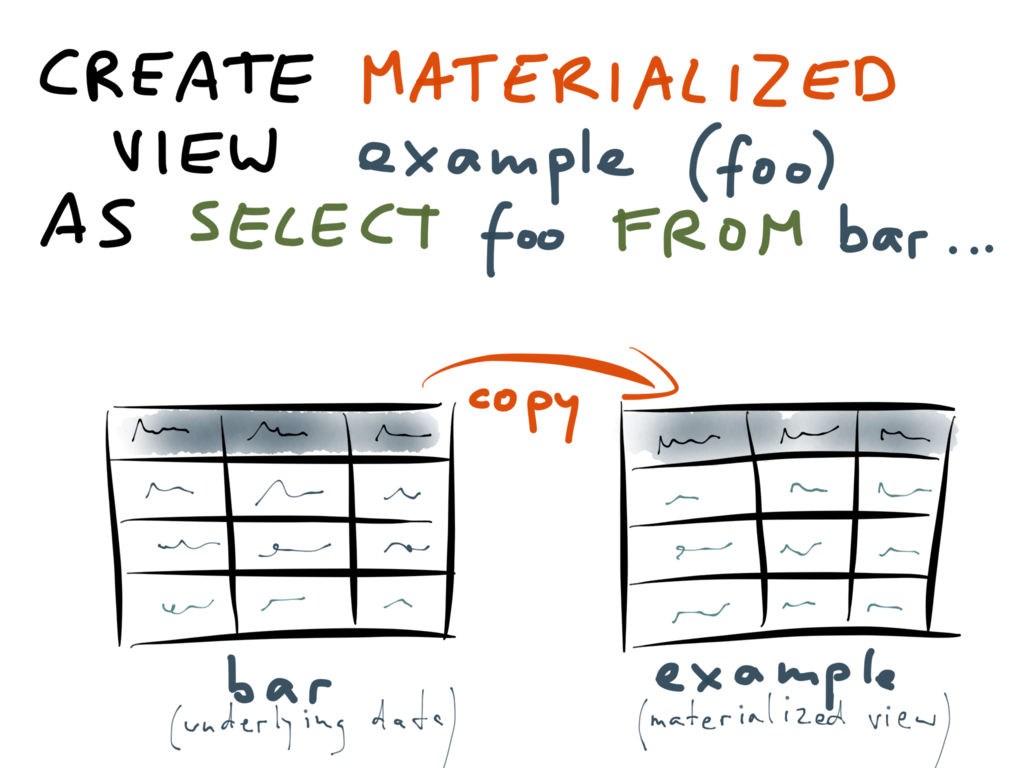
与试图不同,它是物理存在的,并由数据库来确保与主库的一致性
它是随时可以rebuilt from source store,应用是从来不会更新它的: readonly
MySQL没有提供该功能,但通过dbus可以方便构造materialized view
PostgreSQL提供了materialized view
https://docs.microsoft.com/en-us/azure/architecture/patterns/materialized-view
|
|
如果需要的只是eventaul consistency,那么通过dbus来进行cache invalidation是最有效的
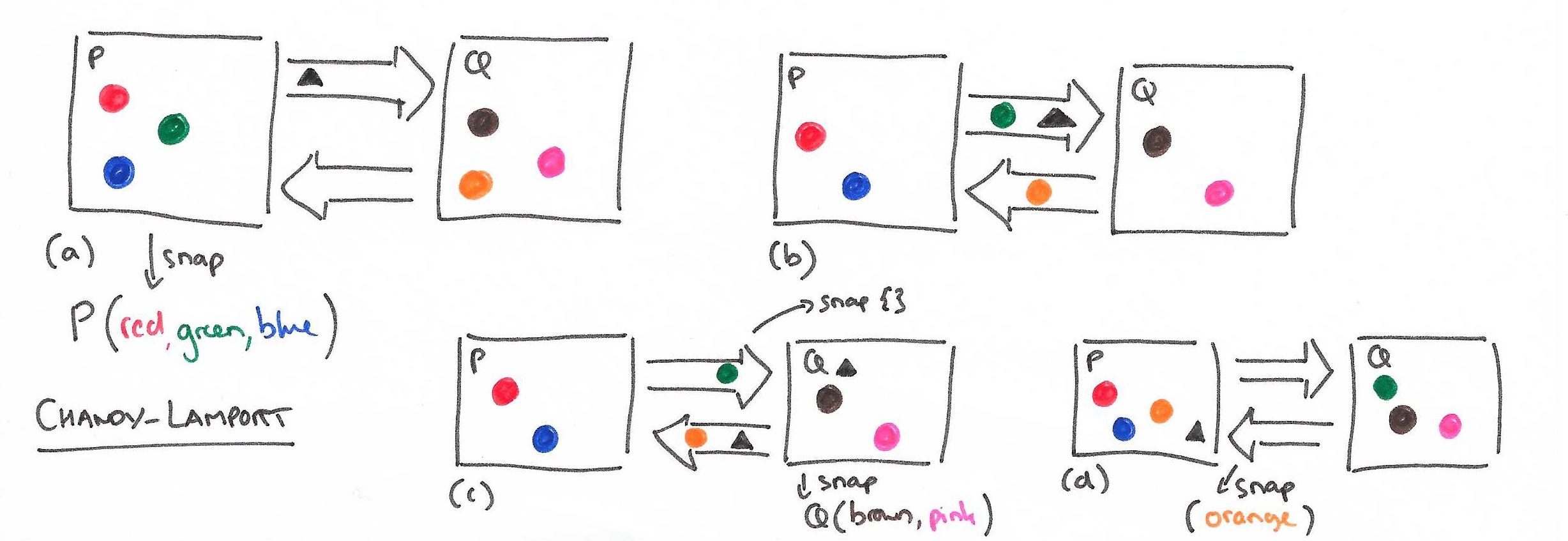
如何给分布式系统做个全局逻辑一致的快照?
Node State + Channel State
|
|
|
|
|
|
发起global distributed snapshot的节点,可以是一台,也可以多台并发
所有节点上都完成了snapshot
故障恢复
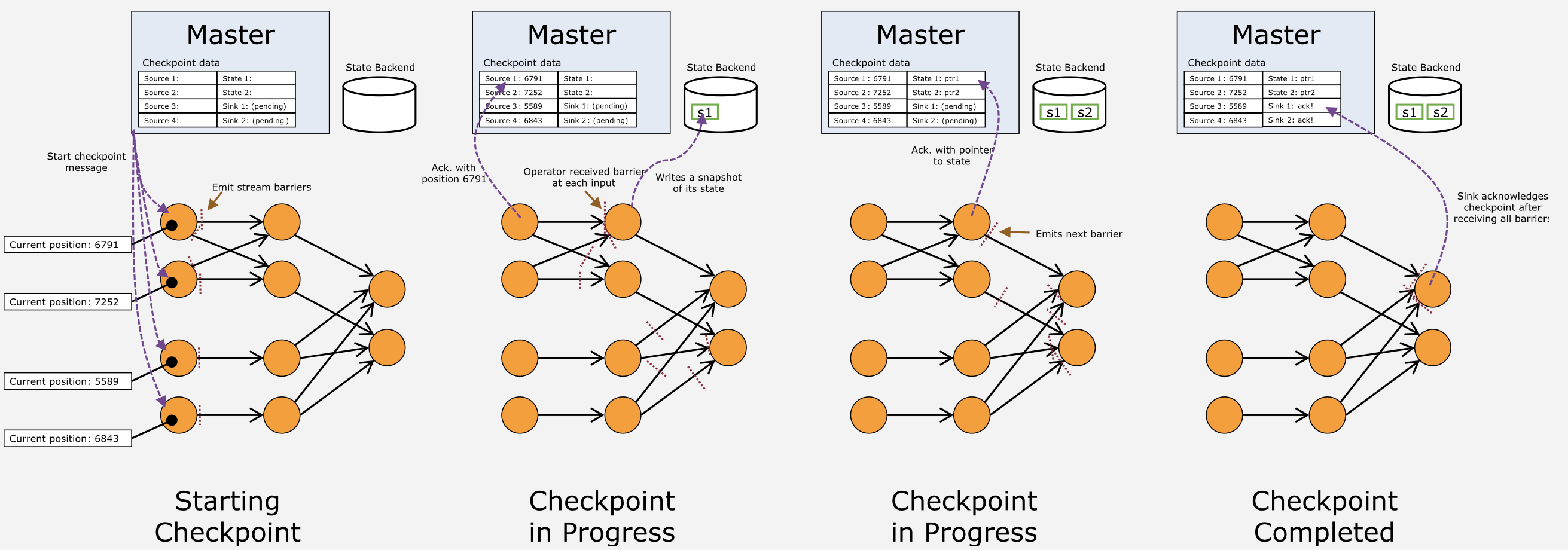
与Apache Storm的基于记录的ack不同,Apache Flink的failure recovery采用了改进的Chandy-Lamport算法
checkpoint coordinator是JobManager
data sources periodically inject markers into the data stream.123val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setParallelism(4)env.enableCheckpointing(1000) // 数据源每1s发送marker(barrier)
Whenever an operator receives such a marker, it checkpoints its internal state.1234567891011121314151617181920212223242526272829303132class StateMachineMapper extends FlatMapFunction[Event, Alert] with Checkpointed[mutable.HashMap[Int, State]] { private[this] val states = new mutable.HashMap[Int, State]() override def flatMap(t: Event, out: Collector[Alert]): Unit = { // get and remove the current state val state = states.remove(t.sourceAddress).getOrElse(InitialState) val nextState = state.transition(t.event) if (nextState == InvalidTransition) { // 报警 out.collect(Alert(t.sourceAddress, state, t.event)) } else if (!nextState.terminal) { // put back to states states.put(t.sourceAddress, nextState) } } override def snapshotState(checkpointId: Long, timestamp: Long): mutable.HashMap[Int, State] = { // barrier(marker) injected from data source and flows with the records as part of the data stream // // snapshotState()与flatMap()一定是串行执行的 // 此时operator已经收到了barrier(marker) // 在本方法返回后,flink会自动把barrier发给我的output streams // 再然后,保存states(默认是JobManager内存,也可以HDFS) states } override def restoreState(state: mutable.HashMap[Int, State]): Unit = { // 出现故障后,flink会停止dataflow,然后重启operator(StateMachineMapper) states ++= state }}
http://research.microsoft.com/en-us/um/people/lamport/pubs/chandy.pdf
https://arxiv.org/abs/1506.08603
https://ci.apache.org/projects/flink/flink-docs-master/internals/stream_checkpointing.html
https://github.com/StephanEwen/flink-demos/tree/master/streaming-state-machine
curl https://baidu.com
How the 270ms passed1234567891011121314151617181920212223242526272829303132333435363738394041424344451 1 0.0721 (0.0721) C>S Handshake ClientHello Version 3.1 cipher suites TLS_EMPTY_RENEGOTIATION_INFO_SCSV TLS_DHE_RSA_WITH_AES_256_CBC_SHA TLS_DHE_RSA_WITH_AES_256_CBC_SHA256 TLS_DHE_DSS_WITH_AES_256_CBC_SHA TLS_RSA_WITH_AES_256_CBC_SHA TLS_RSA_WITH_AES_256_CBC_SHA256 TLS_DHE_RSA_WITH_AES_128_CBC_SHA TLS_DHE_RSA_WITH_AES_128_CBC_SHA256 TLS_DHE_DSS_WITH_AES_128_CBC_SHA TLS_RSA_WITH_RC4_128_SHA TLS_RSA_WITH_RC4_128_MD5 TLS_RSA_WITH_AES_128_CBC_SHA TLS_RSA_WITH_AES_128_CBC_SHA256 TLS_DHE_RSA_WITH_3DES_EDE_CBC_SHA TLS_DHE_DSS_WITH_3DES_EDE_CBC_SHA TLS_RSA_WITH_3DES_EDE_CBC_SHA compression methods NULL1 2 0.1202 (0.0480) S>C Handshake ServerHello Version 3.1 session_id[32]= b3 ea 99 ee 5a 4c 03 e8 e0 74 95 09 f1 11 09 2a 9d f5 8f 2a 26 7a d3 7f 71 ff dc 39 62 66 b0 f9 cipherSuite TLS_RSA_WITH_AES_128_CBC_SHA compressionMethod NULL1 3 0.1205 (0.0002) S>C Handshake Certificate1 4 0.1205 (0.0000) S>C Handshake ServerHelloDone1 5 0.1244 (0.0039) C>S Handshake ClientKeyExchange1 6 0.1244 (0.0000) C>S ChangeCipherSpec1 7 0.1244 (0.0000) C>S Handshake1 8 0.1737 (0.0492) S>C ChangeCipherSpec1 9 0.1737 (0.0000) S>C Handshake1 10 0.1738 (0.0001) C>S application_data1 11 0.2232 (0.0493) S>C application_data1 12 0.2233 (0.0001) C>S Alert1 0.2234 (0.0000) C>S TCP FIN1 0.2709 (0.0475) S>C TCP FIN
分布式事务,为了性能,目前通常提供SI/SSI级别的isolation,通过乐观冲突检测
而非2PC悲观方式实现,这就要求实现事务的causality,通常都是拿逻辑时钟实现total order
例如vector clock就是一种,zab里的zxid也是;google percolator里的total order算是
另外一种逻辑时钟,但这种方法由于有明显瓶颈,也增加了一次消息传递
但逻辑时钟无法反应物理时钟,因此有人提出了混合时钟,wall time + logical time,分别是
给人看和给机器看,原理比较简单,就是在交互消息时,接收方一定sender event happens before receiver
但wall time本身比较脆弱,例如一个集群,有台机器ntp出现问题,管理员调整时间的时候出现人为
错误,本来应该是2017-09-09 10:00:00,结果typo成2071-09-09 10:00:00,后果是它会传染给集群
内所有机器,hlc里的wall time都会变成2071年,人工无法修复,除非允许丢弃历史数据,只有等
到2071年那一天系统会自动恢复,wall time部分也就失去了意义
要解决这个问题,可以加入epoch1234HLC+-------+-----------+--------------+| epoch | wall time | logical time |+-------+-----------+--------------+
修复2071问题时,只需把epoch+1