如何给分布式系统做个全局逻辑一致的快照?
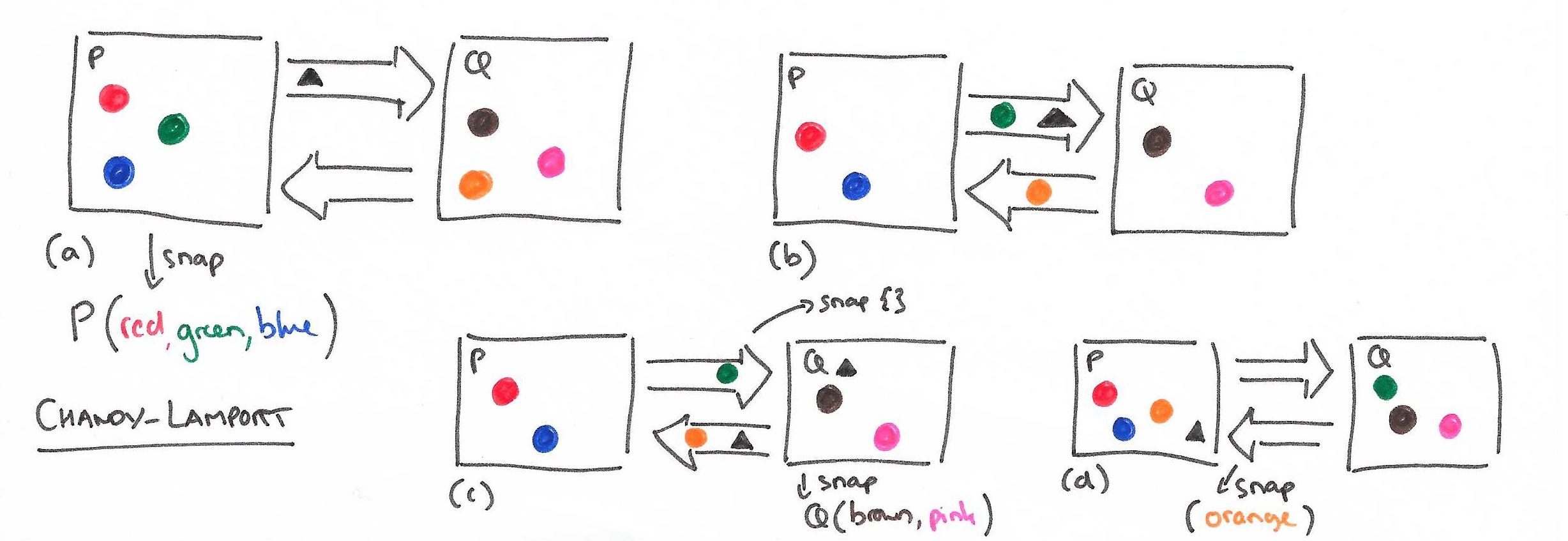
Node State + Channel State
发送规则
|
|
接收规则
|
|
Demo
|
|
FAQ
如何发起
发起global distributed snapshot的节点,可以是一台,也可以多台并发
如何结束
所有节点上都完成了snapshot
用途
故障恢复
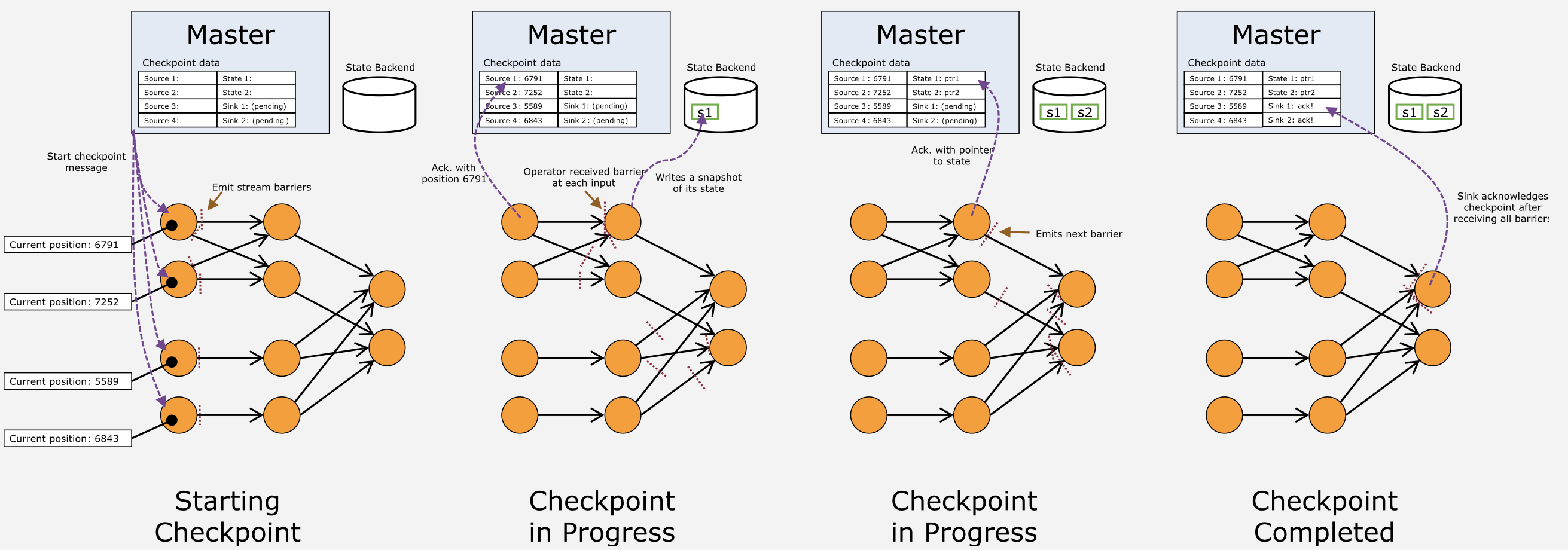
与Apache Storm的基于记录的ack不同,Apache Flink的failure recovery采用了改进的Chandy-Lamport算法
checkpoint coordinator是JobManager
data sources periodically inject markers into the data stream.
Whenever an operator receives such a marker, it checkpoints its internal state.
References
http://research.microsoft.com/en-us/um/people/lamport/pubs/chandy.pdf
https://arxiv.org/abs/1506.08603
https://ci.apache.org/projects/flink/flink-docs-master/internals/stream_checkpointing.html
https://github.com/StephanEwen/flink-demos/tree/master/streaming-state-machine