Intro
纠错码在RAID、备份、冷数据、历史数据存储方面使用广泛
也有人利用它把一份数据分散到多个cloud provider(e,g. S3,Azure,Rackspace),消除某个供应商的依赖: cloud of cloud
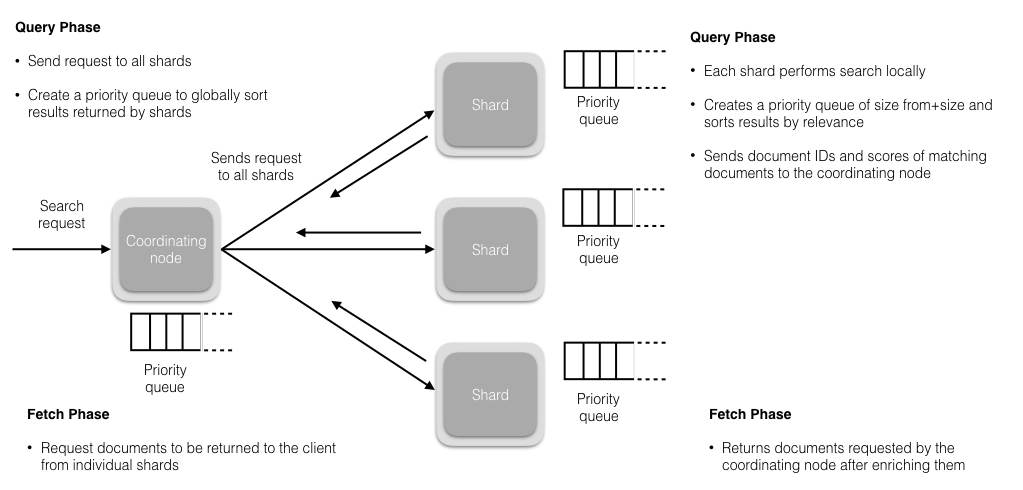
Usage
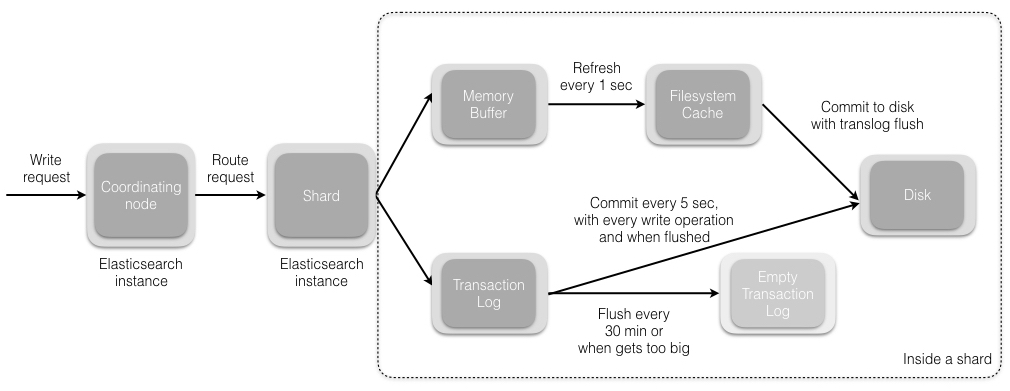
一份文件,大小x,分成n个数据块+k个校验块,能容忍任意k个数据块或者校验块错误,即至少要n个块是有效的
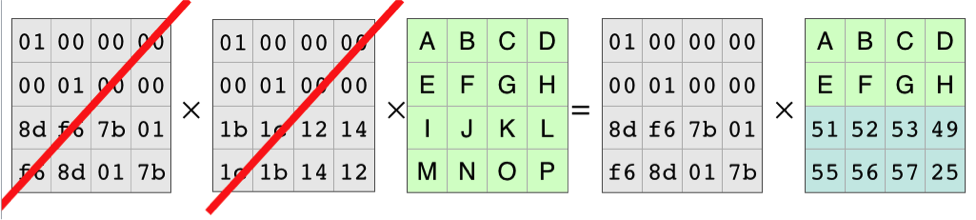
Algorithm
文件内容‘ABCDEFGHIJKLMNOP’,4+2
给定n和k,encoding矩阵是不变的

References
http://pages.cs.wisc.edu/~yadi/papers/yadi-infocom2013-paper.pdf