Basics
Storage Model
一种特殊的LSM Tree
Defaults
|
|
Best Practice
内存,一半给ES,一半给pagecache
Indexing
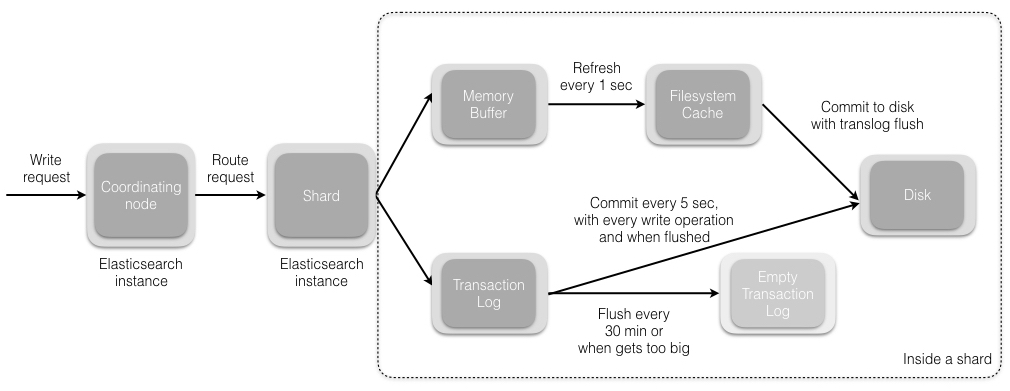
translog(WAL)
- 每个shard一个translog,即每个index一个translog
- 它提供实时的CRUD by docID,先translog然后再segments
- 默认5s刷盘
- translog存放在path.data,可以stripe,但存在与segments竞争资源问题1234$ls nodes/0/indices/twitter/1/drwxr-xr-x 3 funky wheel 102B 6 8 17:23 _statedrwxr-xr-x 5 funky wheel 170B 6 8 17:23 indexdrwxr-xr-x 3 funky wheel 102B 6 8 17:23 translog
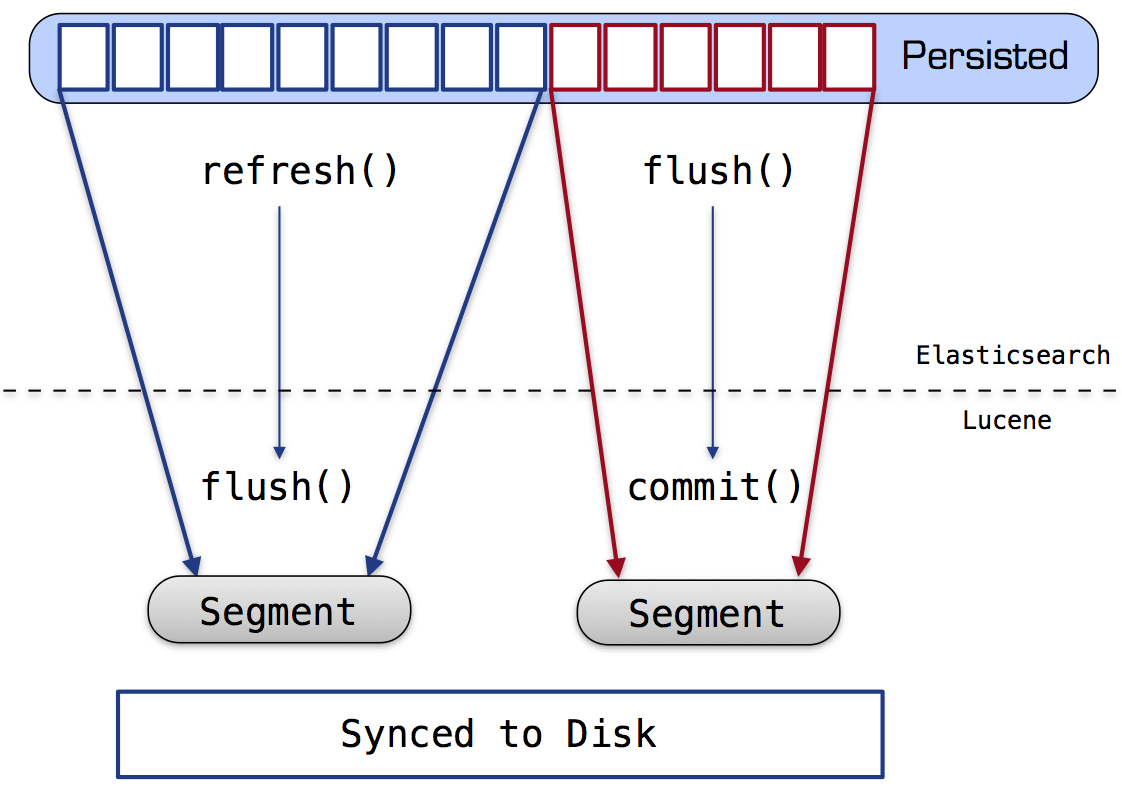
refresh
- on segments
- scheduled periodically(1s),也可手工 /_refresh
- 在此触发merge逻辑
- refresh后,那么在此之前的所有变更就可以搜索了,in-memory buffer的数据是不能搜索的
- 产生新segment,但不fsync(close不会触发fsync),然后open(the new segment)
- 不保证durability,那是由flush保证的
- in-memory buffer清除
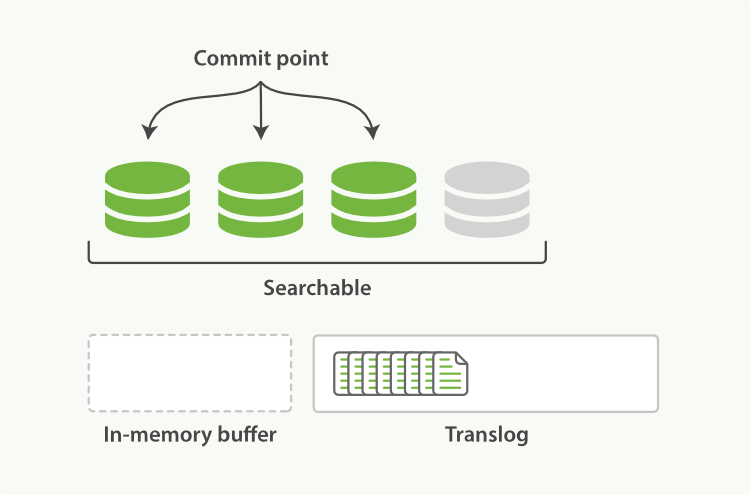
- flush
- on translog
- 30s/200MB/5000 ops by default,会触发commit
- Any docs in the in-memory buffer are written to a new segment
- The buffer is cleared
- A commit point is written to disk
commit point is a file that contains list of segments ready for search - The filesystem cache is flushed with an fsync
- The old translog is deleted
- commit
- 把还没有fsync的segments,一一fsync
- merge
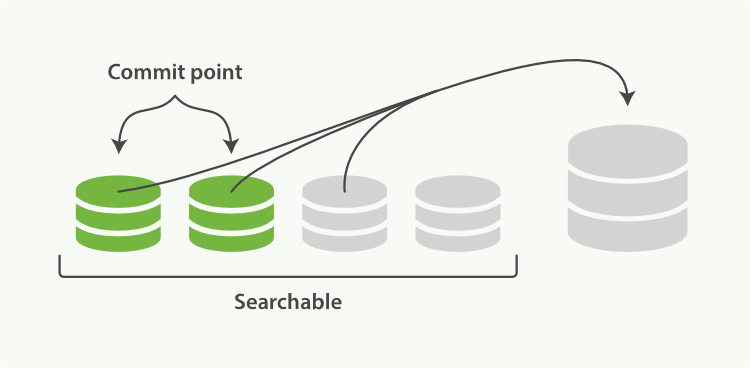
- policy
- tiered(default)
- log_byte_size
- log_doc
- 可能把committed和uncommitted segments一起merge
- 异步,不影响indexing/query
- 合并后,fsync the merged big segment,之前的small segments被删除
- ES内部有throttle机制控制merge进度,防止它占用过多资源: 20MB/s
- update
delete, then insert。mysql内部的变长字段update也是这么实现的
Hard commit
默认30分钟,或者translog size(200MB),whoever come early
|
|
Merge
- Happens in parallel to searching. Searcher is changed to new segment.
- Deleting a document creates a new document and .del file to keep track that document is deleted
- 由于一个document可能多次update,在不同的segment可能出现多次delete
Replication
primary-backup model
master的indexing过程
Query
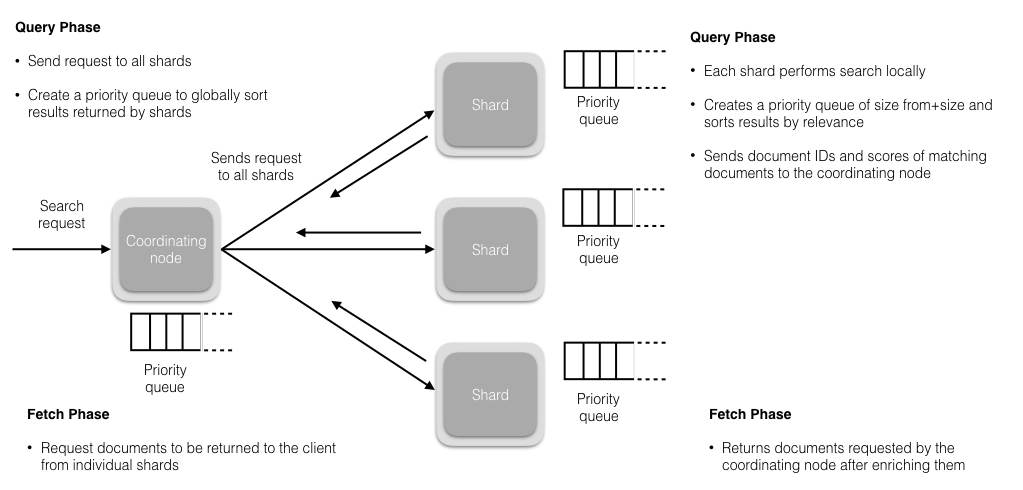
local search
|
|
deep pagination
search(from=50000, size=10),那么每个shard会创建一个优先队列,队列大小=50010,从每个segment里取结果,直到填满
而coordinating node需要创建的优先队列 number_of_shards * 50010
利用scan+scroll可以批量取数据(sorting disabled),例如在reindex时使用
Cluster
Intro
所有node彼此相连,n*(n-1)个连接
shard = MurMurHash3(document_id) % (num_of_primary_shards)
Node1节点用数据的_id计算出数据应该存储在shard0上,通过cluster state信息发现shard0的主分片在Node3节点上,Node1转发请求数据给Node3,Node3完成数据的索引
Node3并行转发(PUSH model replication)数据给分配有shard0的副本分片Node1和Node2上。当收到任一节点汇报副本分片数据写入成功以后,Node3即返回给初始的接受节点Node1,宣布数据写入成功。Node1成功返回给客户端。
Scale
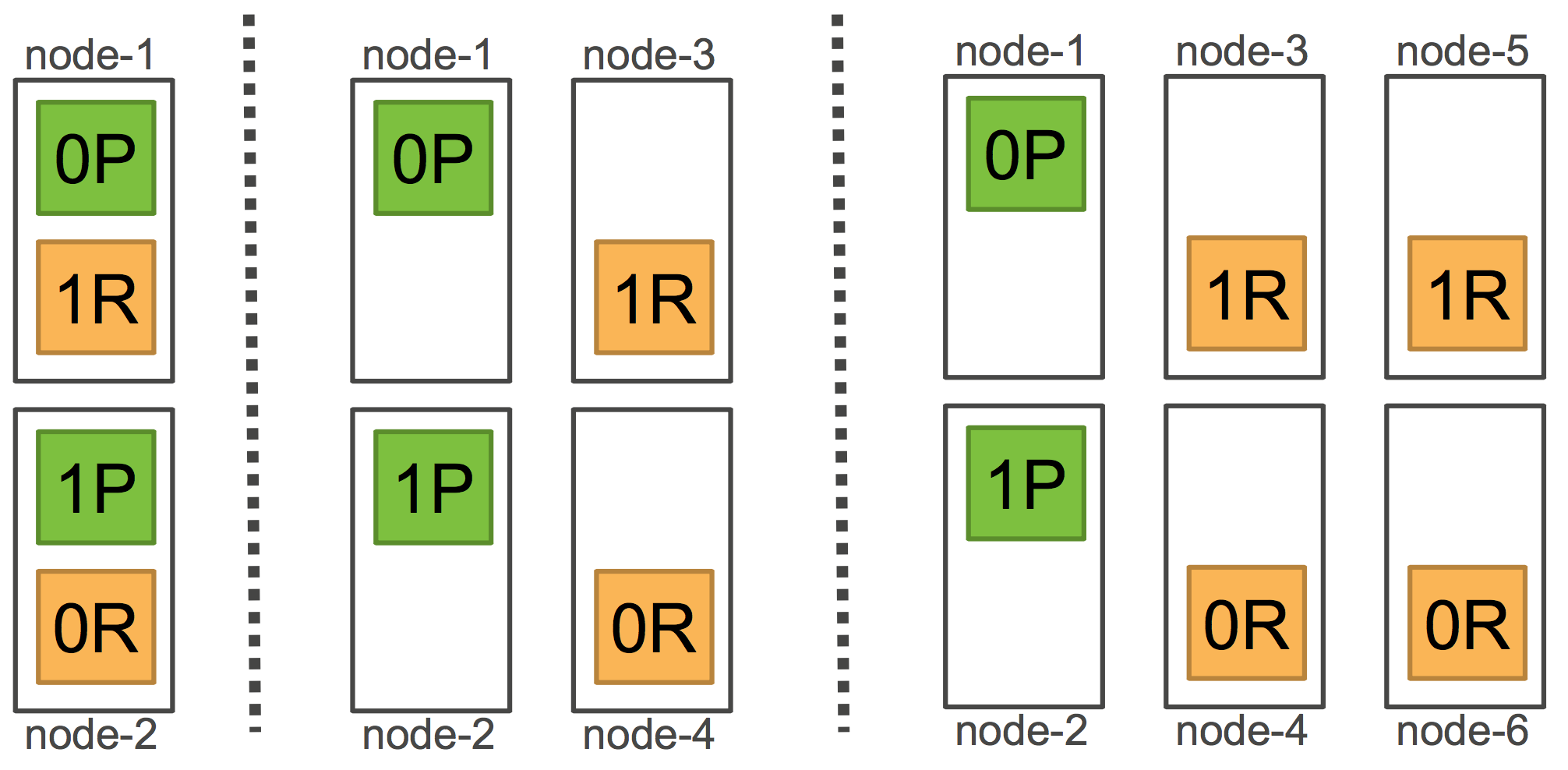
Rebalance
|
|
新节点加入过程
|
|
discovery.zen.ping.unicast.hosts其实是种子,5个node配2个,也可以获取全局节点信息:知一点即知天下
Master fault detection
默认,每个node每1s ping master,ping_timeout=30s,ping_retries=3
失败后,会触发new master election
Concurrency
每个document有version,乐观锁
Consistency
- quorum(default)
- one
- all
Shard
allocation
|
|
如果计算最后的weight(node, index)大于threshold, 就会发生shard迁移。
在一个已经创立的集群里,shard的分布总是均匀的。但是当你扩容节点的时候,你会发现,它总是先移动replica shard到新节点。
这样就导致新节点全部分布的全是副本,主shard几乎全留在了老的节点上。
cluster.routing.allocation.balance参数,比较难找到合适的比例。
初始化
|
|
Shrink Index
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-shrink-index.html
并不是resharding,开始时可以创建很多shard(e,g. 30),用来灌数据,等数据好了,可以shrink到5
它只是hard link segments,执行时要先把index置为readonly
场景,例如tsdb,按照月份建索引,过了这个月,就可以shrink了
Consensus
zen discovery(unicast/multicast),存在脑裂问题,没有去解决,而是通过3台专用master机器,优化master逻辑,减少由于no reponse造成的partition可能性
默认ping_interval=1s ping_timeout=3s ping_retries=3 join_timeout=20*ping_interval
没有使用Paxos(zk)的原因:
This, to me, is at the heart of our approach to resiliency.
Zookeeper, an excellent product, is a separate external system, with its own communication layer.
By having the discovery module in Elasticsearch using its own infrastructure, specifically the communication layer, it means that we can use the “liveness” of the cluster to assess its health.
Operations happen on the cluster all the time, reads, writes, cluster state updates.
By tying our assessment of health to the same infrastructure, we can actually build a more reliable more responsive system.
We are not saying that we won’t have a formal Zookeeper integration for those who already use Zookeeper elsewhere. But this will be next to a hardened, built in, discovery module.
ClusterState
master负责更改,并广播到机器的每个节点,每个节点本地保存
如果有很多index,很多fields,很多shard,很多node,那么它会很大,因此它提供了增量广播机制和压缩
|
|
Internal Data Structures and Algorithms
Roaring bitmap
T-Digest Percentiles
HDRHistogram Percentiles
Use Cases
github
之前用Solr,后来改为elasticsearch,运行在多个集群。
其中,存储代码的集群26个data node,8 coordinator node,每个data node有2TB SSD,510 shards with 2 replicas
References
https://www.elastic.co/blog/resiliency-elasticsearch
https://github.com/elastic/elasticsearch/issues/2488
http://blog.mikemccandless.com/2011/02/visualizing-lucenes-segment-merges.html
http://blog.trifork.com/2011/04/01/gimme-all-resources-you-have-i-can-use-them/
https://github.com/elastic/elasticsearch/issues/10708
https://github.com/blog/1397-recent-code-search-outages
https://speakerd.s3.amazonaws.com/presentations/d7c3effadc8146a7af6229d3b5640162/friday-colin-g-zach-t-all-about-es-algorithms-and-data-structiures-stage-c.pdf