Models
- primary-replica(failover, replica readable)/multi-master/chain
- replica/ec
- push/pull
- sync/async
|
|
|
|
Babbysitter & GlobalWorkQueue -> cgroup -> Borg -> Omega -> Kubernetes
容器提供的隔离还不完善,OS无法管理的,容器无法隔离(例如CPU Cache,内存带宽),为了防止(cloud)恶意用户,需要在容器外加一层VM保护
container = isolation + image
数据中心:机器为中心 -> 应用为中心
在Application与OS之间增加一层抽象:container
container的依赖大部分都存放在image了,除了OS的系统调用
实际上,应用仍然会受OS影响,像/proc, ioctl
Object是最终落地存储文件的基本单位,可以类比fs block,默认4MB
如果一个文件 > object size,文件会被stripped,这个操作是client端完成的
It does not use a directory hierarchy or a tree structure for storage
It is stored in a flat-address space containing billions of objects without any complexity
Object组成
|
|
|
|
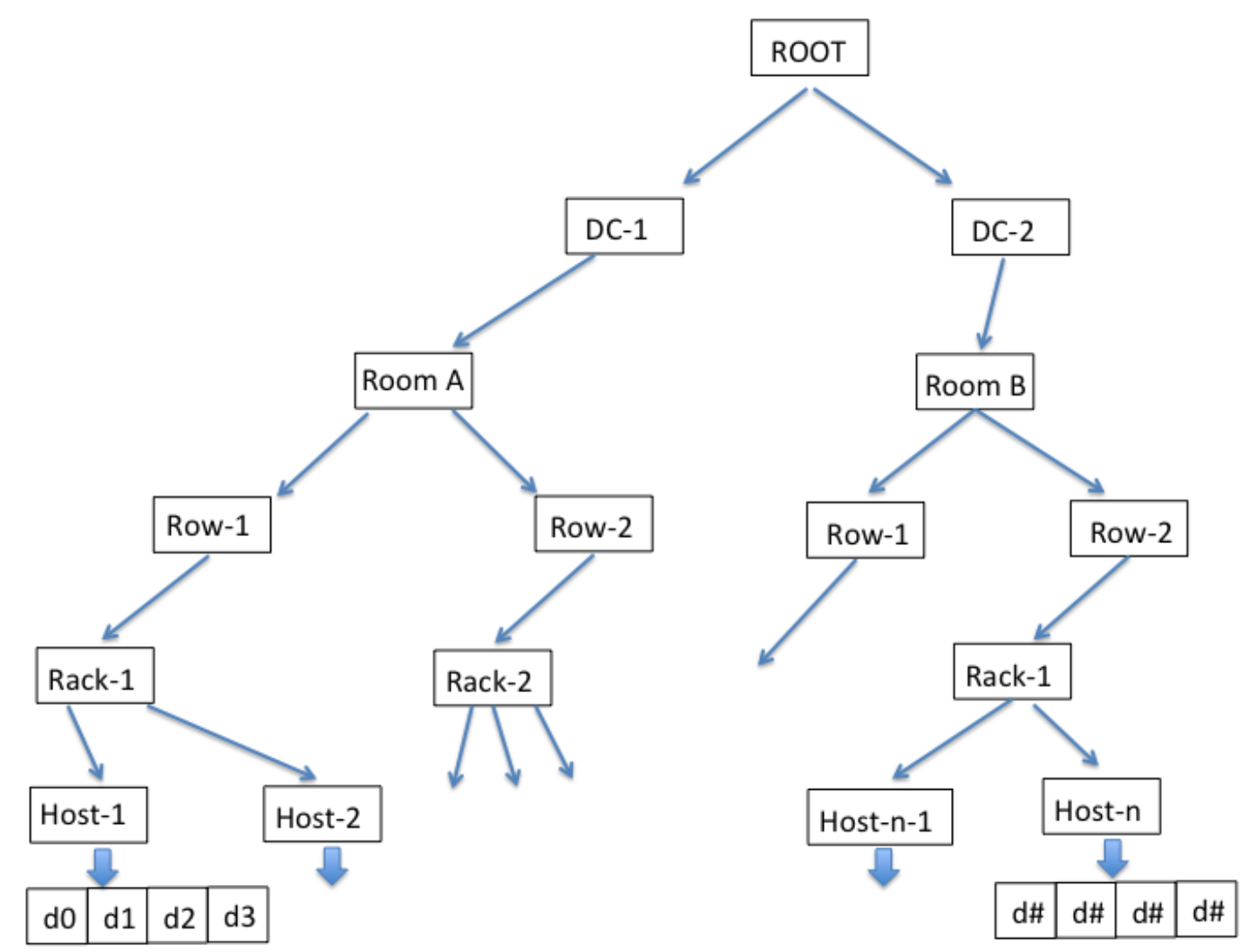
一个hash算法,目标
有点像一致性哈希:failure, addition, removal of nodes result in near-minimal object migration
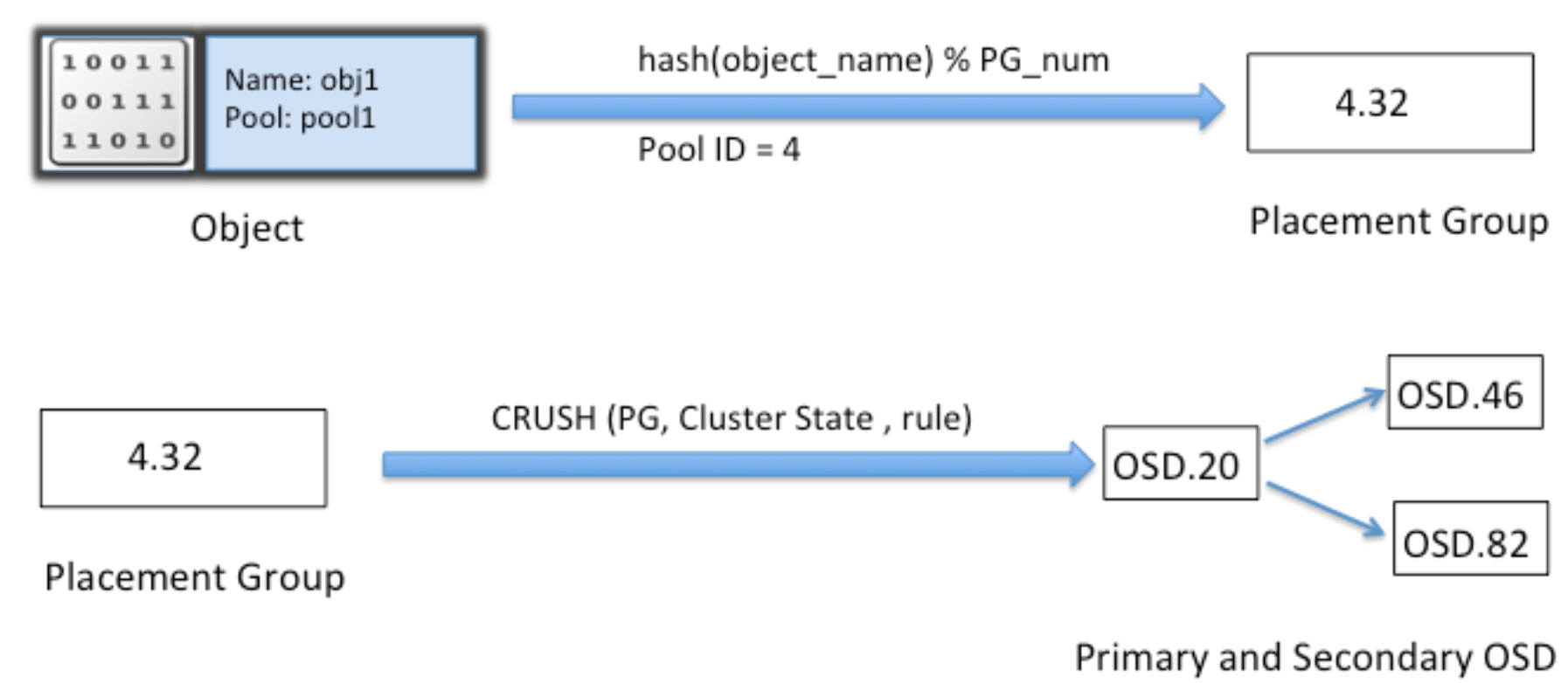
PG(placement group)与Couchbase里的vbucket一样,codis里也类似,都是presharding技术
在object_id与osd中间增加一层pg,减少由于osd数量变化造成大量的数据迁移
PG使得文件的定位问题,变成了通过crush定位PG的问题,数量大大减少
例如,1万个osd,100亿个文件,30万个pg: 100亿 vs 30万
线上尽量不要更改PG的数量,PG的数量的变更将导致整个集群动起来(各个OSD之间copy数据),大量数据均衡期间读写性能下降严重
|
|
|
|
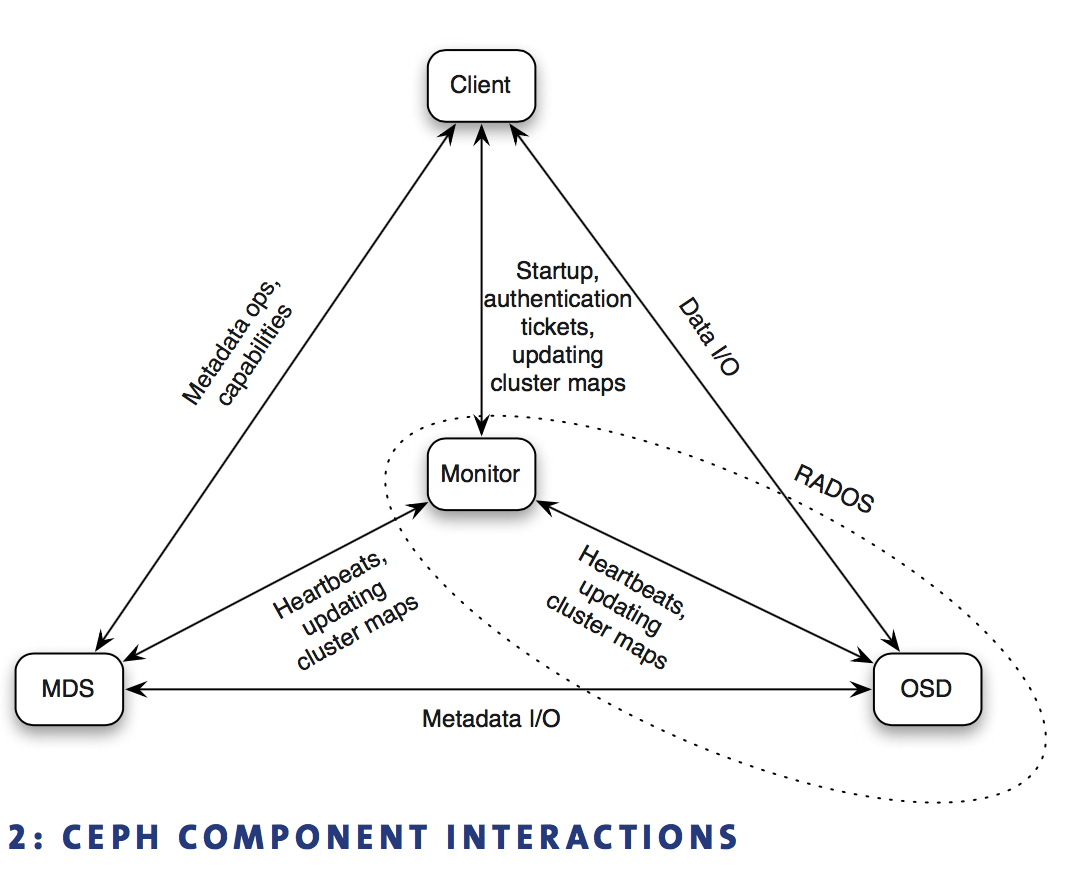
同一个PG内的osd通过heartbeat相互检查对方状态,大部分情况下不需要mon参与,减少了mon负担
相当于Ceph的zookeeper
mon quorum负责整个Ceph cluster中所有OSD状态(cluster map),然后以增量、异步、lazy方式扩散到each OSD和client
mon被动接收osd的上报请求,作为reponse把cluster map返回,不主动push cluster map to osd
如果client和它要访问的PG内部各个OSD看到的cluster map不一致,则这几方会首先同步cluster map,然后即可正常访问
MON跟踪cluster状态:OSD, PG, CRUSH maps
同一个PG的osd除了向mon发送心跳外,还互相发心跳以及坚持pg数据replica是否正常
是primary-replica model, 强一致性,读和写只能向primary发起请求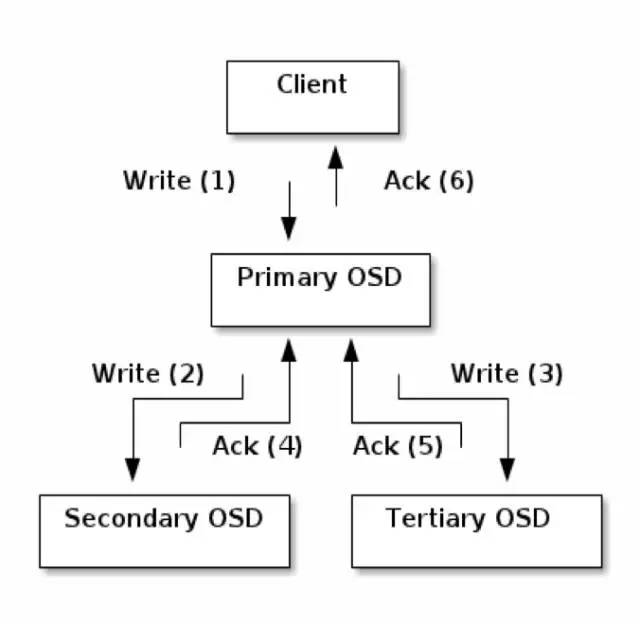
其中replicas在复制到buffer时就ack,如果某个replica复制时失败,进入degrade状态
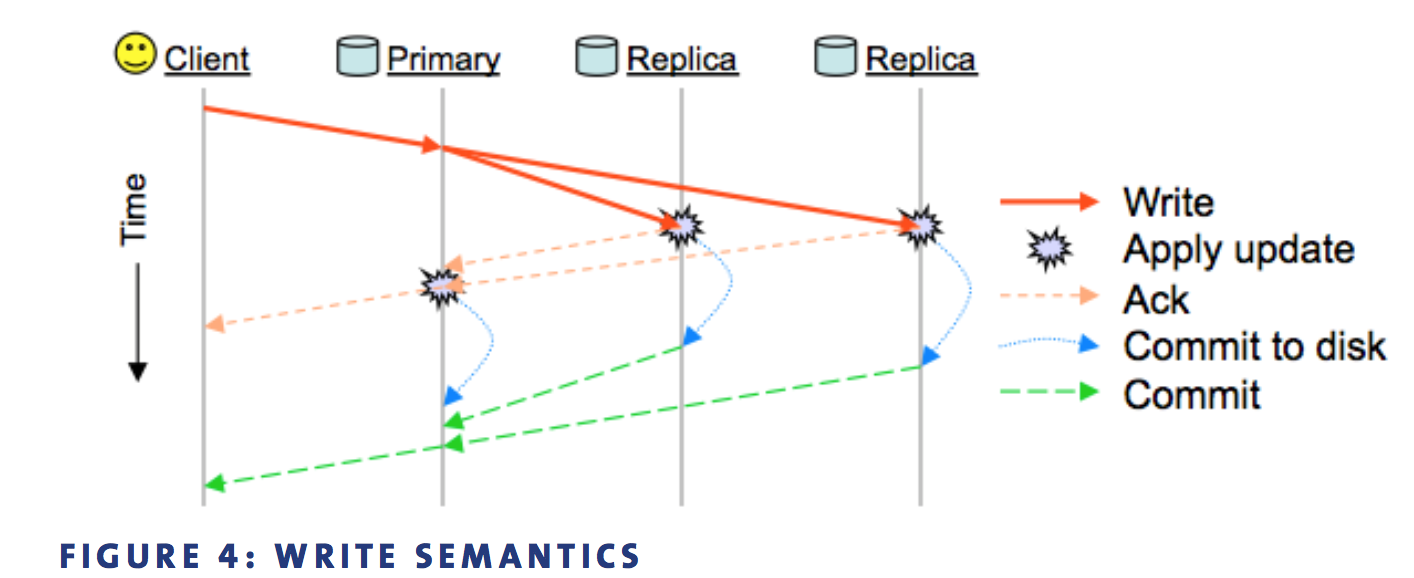
|
|
read verify
strongly consistent
Haystack解决的实际上是metadata访问造成的IO问题,解决的方法是metadata完全内存,无IO
每个图片的read,需要NetApp进行3次IO: dir inode, file inode, file data
haystack每个图片read,需要1次IO,metadata保证在内存
在一个4TB的SATA盘存储20M个文件,每个inode如果需要500B,那么如果inode都存放内存,需要10GB内存
用户上传一张图片,facebook会将其生成4种尺寸的图片,每种存储3份,因此写入量是用户上传量的12倍。
Posix规范里的metadata很多对图片服务器不需要,12345678910111213141516struct inode { loff_t i_size; // 文件大小 struct list_head i_list; // backing dev IO list struct list_head i_devices; blkcnt_t i_blocks; struct super_block *i_sb; struct timespec i_atime; struct timespec i_mtime; struct timespec i_ctime; umode_t i_mode; uid_t i_uid; gid_t i_gid; dev_t i_rdev; unsigned int i_nlink; ...}
Ceph解决了一个文件到分布式系统里的定位问题(crush(pg)),但osd并没有解决local store的问题: 如果一个osd上存储过多文件(例如10M),性能会下降明显
Google Colossus采用的是(6,3)EC,存储overhead=(6+3)/6=150%
把数据分成6个data block+3个parity block,恢复任意一个数据块需要6个I/O
生成parity block和恢复数据时,需要进行额外的encode/decode,造成性能损失
object size是可以设置的
http://ceph.com/papers/weil-crush-sc06.pdf
http://ceph.com/papers/weil-rados-pdsw07.pdf
http://ceph.com/papers/weil-ceph-osdi06.pdf
http://www.xsky.com/tec/ceph72hours/
https://blogs.rdoproject.org/6427/ceph-and-swift-why-we-are-not-fighting
https://users.soe.ucsc.edu/~elm/Papers/sc04.pdf
Joydeep Sen Sarma,印度人,07-11在facebook担任Data Infrastructure Lead,目前在一个创业公司任CTO
在facebook期间,从0搭建了数千节点的hadoop集群,也是Cassandra的core committer,参与开发Hive
https://www.linkedin.com/in/joydeeps/
编写在2009年,Dynamo paper发布于2007
作者主要以Cassandra的实现来评论Dynamoc论文,从而忽略了vector clock逻辑时钟来跟踪数据版本号来检测数据冲突
因此,遭到很多围观群众的声讨
作者的主要思想是:由于hinted handoff,缺少central commit log,缺少resync/rejoin barrier,transient failure会导致stale read
Cassandra解决办法,是尝试通过central commit log,那就变成了Raft了
https://issues.apache.org/jira/browse/CASSANDRA-225
作者如果提到下面的场景,可能更有说服力12345678910// W=3 R=3 N=5(1,2,3,4,5)Op W R==== ===== =====a=5 1,2,3 3,4,5 // 由于有节点overlap,写入的数据可以读出来2,3crash del(a) 1,4,52,3recover 1,2,3 // 2,3读出a=5,而1没有key(a),如何处理冲突?
此外,由于sloppy quorum,下面的场景R+W>N也一样无法保证一致性123456789101112// W=3 R=3 N=5(1,2,3,4,5)ring(A, B, C, D, E, F, G, A)client set(k1)=3 // md5(k1),发现它的coordinator是A,client send req to AA会先写本地磁盘,然后并发向B,C复制,成功后,return to client ok现在A, B, C全部crashset(k1)=8 // 由于hinted handoff,它的coordinator变成DD写盘、复制到E,F,ok。// 当然D,E,F里的数据有hint metadata,表示他们只是代替A,B,C // 等A,B,C活,再transfer to them and cleanup local store然后A, B, C全部recoverget(k1),读到是3,而不是8// 因为D,E,F的检测A/B/C活以及transfer hinted data是异步的
如果一个node crash,’hinted handoff’会把数据写入一致性哈希环上的下一个node:可能是另外一个DC node
等crashed node恢复,如果网络partitioned,这个node会很久无法赶上数据,直到partition解除
但preference list里,已经考虑到了,每个key都会复制到不同的机房
Dynamo SOSP论文有2个目的
本论文不是一个blueprint,拿它就可以做出一个Dynamo clone的
我认为我的论文真正的贡献,是让人设计系统时的权衡trade-off
Java实现的,通过md5(key)进行partition,由coordinator node复制read/write/replicate到一致性哈希虚拟节点环上
gossip进行membership管理和健康检查,提出了R/W/N的quorum模式
每个key都被复制在N台机器(其中一台是coordinator),coordinator向顺时针方向的N-1个机器复制
preference list is list of nodes that is responsible for storing a particular key,通常>N,它是通过gossip在每个节点上最终一致1234567891011121314okN = 0for node = range preferenceList { // 论文中没有提到复制是顺序还是并发 // 如果顺序,latency是个问题 // 如果并发,为了HA和latency,>N个节点会进行复制,造成空间浪费 if replicateTo(node) == ok { okN++ } // all read/write are performed on the first N healthy nodes from pref list if okN == N { break }}
Merkle树123456789node ring(A, B, C, D, E, A), W=3A crash那么本来应该复制到A的数据,会复制到D由于membership change是显示的,D知道这个数据是它临时替A代管的,它会写到临时存储,并携带hint(A) meta info,并定期检查A是否recover如果A ok,D会把本来该写到A的数据transfer给A,成功后,本地删除但,如果D永久crash,而A recover,那么这些hinted data,A就无从transfer了此时,通过Merkle进行检查、增量同步但它的问题是当有node进入、离开时,这个树要重新创建,在key多的时候非常费时,因此,它只能异步后台执行
只是在preference list上配一下,架构上并没有过多考虑
仍然是coordinator负责复制,首先本地机房,然后远程机房
http://jsensarma.com/blog/?p=55
http://jsensarma.com/blog/?p=64
https://timyang.net/data/dynamo-flawed-architecture-chinese/
https://news.ycombinator.com/item?id=915212
http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
都是数据库领域的权威
2008年1月,一个数据库专栏读者让作者表达一下对MapReduce(OSDI 2004)的看法而引出
从IBM IMS的第一个数据库系统(1968)到现在的40年,数据库领域学到了3个经验,而MapReduce把这些经验完全摒弃,仿佛回到了60年代DBMS还没出现的时候
他们应该好好学学25年来并行数据库方面的知识
在非full scan场景下,index必不可少。此外,DBMS里还有query optimizer,而MapReduce里只能brute force full scan
MapReduce能提供自动的并行执行,但这些东西80年代就已经在学术界研究了,并在80年代末出现了类似Teradata那样的商业产品
David J. DeWitt在并行数据库方向已经找到了解决方案,但MapReduce没有使用,好像skew问题根本不存在一样:
Map阶段,相同key的记录数量是不均衡的,这就导致Reduce阶段,有的reduce快、有的慢,最终Job的执行时间取决于最慢的那一个
|
|
而并行数据库,采用的是PUSH模型。而MapReduce要修改成PUSH模型是比较困难的,因为它的HA非常依赖它目前的PULL模型
MapReduce uses a pull model for moving data between Mappers and Reducers
(Jeff:
承认了这个问题的存在。但google在实现的时候,通过batching, sorting, grouping of intermediate data and smart scheduling of reads缓解了这个问题
只所以使用PULL MODEL,是考虑到容错。大部分MR Job都会遇到几次错误,除了硬件、软件错误外,Google内部的调度系统是抢占式的:它可能会把M/R kill以疼出资源给更高优先级的进程,如果PUSH,那么就需要重新执行所有的Map任务)
他们以为他们发现了一个解决大数据处理的新模式,实际上20年前就有了
“Application of Hash to Data Base Machine and Its Architecture”/1983,是第一个提出把大数据集切分成小数据集的
Teradata使用MapReduce同样的技术卖他们的商业产品已经20多年了
就算MapReduce允许用户自己写map/reduce来控制,80年代中期的POSTGRES系统就支持用户自定义函数
作者已经发行类似Pig那样的系统
作者好像觉得MR是用来替代DBMS的
http://cs.smith.edu/dftwiki/images/3/3c/MapReduceFlexibleDataProcessingTool.pdf
按照USnews的分类,Computer Science被分为四个大类:AI, Programming Language, System, Theory
PSU的CiteSeer(又名ResearchIndex),有各个会议的影响因子,算是比较权威的
包括OS、Architecture、Network、Database等
OSDI、SOSP,这两个是OS最好的会议,每两年开一次,轮流开
数据库方向的三大顶级会议,SIGMOD和VLDB算是公认第一档次
http://blog.sina.com.cn/s/blog_b3b900710102whvj.html
http://sigops.org/sosp/sosp15/current/index.html
Language Integrated Query,一个C#的语言特性,基本思想是在语言层面增加了query的能力
在通过GraphQL中,应该可以发挥它的能力,来进行聚合、过滤、排序等
大数据,主要是因为Google的Google File System(2003), MapReduce(OSDI 2004),BigTable(2006)三篇论文
GFS论文是最经典的,后面google的很多论文都遮遮掩掩的
Chubby(2006)
Dremal(2010)
Borg(2015)
微软在bing项目上的投入,使得微软掌握了大规模data center的建设管理能力,掌握了A/B testing平台,学会了大规模数据分析能力,其中一些成为了Azure的基础,它使得微软顺利从一家软件公司过渡到了云计算公司。
微软内部支撑大数据分析的平台Cosmos是狠狠的抄袭了Google的File system却很大程度上摒弃了MapReduce这个框架
所谓MapReduce的意思是任何的事情只要都严格遵循Map Shuffle Reduce三个阶段就好。其中Shuffle是系统自己提供的而Map和Reduce则用户需要写代码。Map是一个per record的操作。任何两个record之间都相互独立。Reduce是个per key的操作,相同key的所有record都在一起被同时操作,不同的key在不同的group下面,可以独立运行
Map是分类(categorize)操作,Reduce是aggregate
To draw an analogy to SQL, map is like the group-by clause of an aggregate query. Reduce is analogous to the aggregate function (e.g., average) that is computed over all the rows with the same group-by attribute.
Flume Java本质上来说还是MapReduce,但是它采取了一种delayed execution的方式,把所有相关的操作先存成一个execution DAG,然后一口气执行。
这和C#里的LINQ差不多。这种方式就产生了很多optimization的机会了。具体来说大的有两个:
Hadoop三大批发商分别是Cloudera,Hortonworks以及MapR。
MapR(印度人CTO是Google GFS项目组,后用C++写了自己的HDFS)、Cloudera(源于BerkeleyDB卖给Oracle)都成立于2009年,Hortonworks(源于Yahoo Hadoop分拆) 2011,目前Cloudera一家独大
Hortonworks基本上就是Yahoo里的Hadoop团队减去被Cloudera挖走的Doug Cutting, Hadoop的创始人。这个团队的人做了不少东西,最初的HDFS和Hadoop MapReduce, ZooKeeper,以及Pig Latin。
MapR的印度人CTO,目前已经跳槽到了Uber
Hortonworks本来是一个发明了Pig的公司。Pig是它们的亲儿子。现在他们作为一个新成立的公司,不像Cloudera或者MapR那样另起炉灶,却决定投入HIVE的怀抱,要把干儿子给捧起来
Pig发表在SIGMOD2008,之后Hive也出来了
时至今日,我们必须说Pig是被大部分人放弃了:原来做Pig的跑去了Hortonworks,改行做Hive了
HIVE已经事实上成为了Hadoop平台上SQL和类SQL的标杆和事实的标准。
2008年Hadoop的一次会议,facebook的2个印度人讲了他们hackathon的项目Hive,他们说SQL的SELECT FROM应该是FROM SELECT
2010年Hive论文发表,直到2014年那2个印度人一直在Hive PMC,后来出来创业大数据公司
后来,做Pig的人看上了Hive,Hortonworks把自己人塞进PMC,现在那2个印度人已经除名了,Hive基本上是Hortonworks和Cloudera的天下,Cloudera做企业需要的安全方面东西,Hortonworks做性能提升
于是,Pig的人成了Hive主力,做Hive的人跑光了
Dynamo: A flawed architecture
http://jsensarma.com/blog/?p=55
Hbase开始的时候是一个叫Powerset的公司,这个公司是做自然语言搜索的。公司为了能够实现高效率的数据处理,做了HBase。2008年的时候这个公司被卖给了微软
VLDB(Very Large Data Base), 世界数据库业界三大会议之一;另外两个是ICDE和sigmod,另外还有KDD。
在数据库领域里面,通常SIGMOD和VLDB算是公认第一档次,ICDE则是给牛人接纳那些被SIGMOD VLDB抛弃的论文的收容所,勉强1.5吧,而且有日渐没落的趋势。
CIDR在数据库研究领域是个奇葩的会议,不能说好不能说不好。因为是图灵机得主Michael Stonebraker开的,给大家提供个自娱自乐的场所。所以很多牛人买账,常常也有不错的论文。但是更多的感觉是未完成的作品。
Dremal出来没多久,开源社区,尤其是Hadoop的批发商们都纷纷雀跃而起。Cloudera开始做Impala,MapR则做了Drill,Hortonworks说我们干脆直接improve HIVE好了,所以就有了包括Apache Tez在内的effort
Dremal的存储是需要做一次ETL这样的工作,把其他的数据通过转化成为它自己的column store的格式之后才能高效率的查询的。
Dremal出来后,Cloudera 2012年做出了Impala,MapR搞了个Drill,Hortonworks也许最忽悠也许最实际,说我们只需要改善 Hive就好
Spark是迄今为止由学校主导的最为成功的开源大数据项目
UCBerkeley作为一个传统上非常有名的系统学校,它曾经出过的系统都有一个非常明确的特点,可用性非常高
hadoop的存储格式:TextFile, SequenceFile, Hive优化的RCFile, 类似google dremel的Parquet
Data placement for MapReduce
一种PAX的实现:Table先水平切分成多个row group,每个row group再垂直切分到不同的column
这样保证一个row的数据都位于一个block(避免一个row要读取多个block),列与列的数据在磁盘上是连续的存储块
table = RCFile -> block -> row group -> (sync marker, metadata header(RLE), column store(gzip))
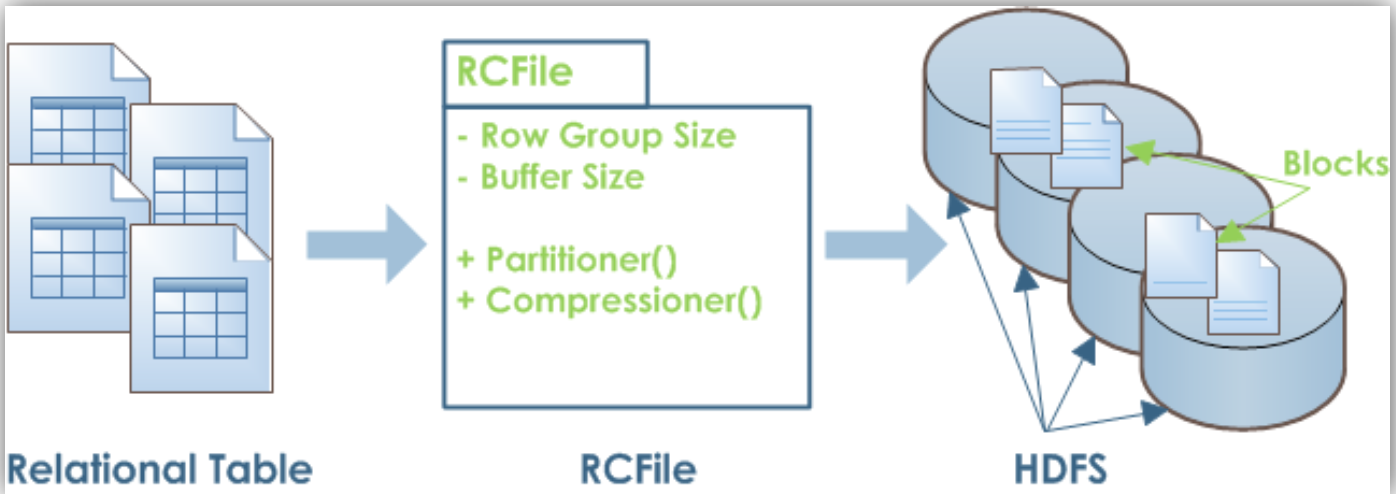
For a table, all row groups have the same size.
ql/src/java/org/apache/hadoop/hive/ql/io/RCFile.java
|
|
http://web.cse.ohio-state.edu/hpcs/WWW/HTML/publications/papers/TR-11-4.pdf
http://www.ece.eng.wayne.edu/~sjiang/ECE7650-winter-14/Topic3-RCFile.pdf