GFS
GFS,2001年开发出来,3个人,1年,论文发表于2003
BigTable,2004年开发出来,论文发表于2006
master
- replicated operation(redo) log with checkpoint to shadow masters
- 当时没有自动failover,全是人工操作DNS alias
- read请求可以使用shadow masters
- 生成checkpoint时,master切换到新的redo log file,创建新线程生成checkpoint
在此过程中发生的变化,记录到新redo log file - operation log保证了mutation的全局有序
- save checkpoint
很可能是通过mmap+msync
- bottleneck?
- 当时部署了多个cluster,根据业务属性
最大的超过1000节点,300TB - 过高的OPS
由于redo log需要复制,master的tps也就在1万左右- client cache
何时invalidate and recall master?- primary unreachable
- primary reponse: no lease
- client batch request
- lease
- client cache
- 内存容量
- prefix compression to reduce memory footprint
- 每个chunk(64MB),metadata占内存64B
如果保存1百万个文件(64TB),需要64MB内存
如果保存10亿个文件(64PB),需要64GB内存
实际上是到了5千万个文件,10PB的时候,master已经到达瓶颈了
- 当时部署了多个cluster,根据业务属性
metadata
|
|
delete
rename to hidden file,保留3天,之后真正删除
write/mutation
- operation log replicated between master and shadows
- client write data flow to pipelined chain chunkservers
- primary write control flow to secondary chunkservers
read(filename, offset, size)
|
|
磁盘错误的解决
file -> chunk -> block
在每个chunkserver上执行,通过checksum检测
每个chunk由多个64KB的block组成,每个block有一个32位的checksum
read repair,如果chunkserver发现了一个非法block,会返回client err,同时向master汇报
- client会从其他replica read
- master会从其他有效的replica把这整个chunk clone到另外一个chunkserver,然后告诉有问题的chunkserver删除那个chunk
Questions
chunk为什么64MB那么大?
- 减少master内存的占用
- 减少client与master的交互
同一个chunk的R/W,client只需要与master交互一次 - 可以很容易看到机器里哪些机器磁盘快满了,而做迁移
- 可以减少带宽的hotspot
如果没有chunk,那么1TB的文件就只能从一个replica读
有了chunk,可以从多个replica读 - sharding the load
- 加快recovery时间
每个chunk,可以很快地被clone到一台新机器 - 如果一个file只有1MB,那么实际存储空间是1MB,而不是64MB
但它会增加master file count问题 - 可以独立replicate
- 文件的一部分损坏,可以迅速从好的replica恢复
- 支持更细粒度的placement
- 支持超大文件
chunk hotspot问题
MapReduce时,需要把代码发布到GFS,很可能小于64MB,即只有1个chunk,当很多mapper时,这个chunkserver就成为hotspot
解决办法是:增加replication factor
但最终的解决方案是:client间P2P,互相读
master为什么不用Paxos?
master通过redo log sync replication来提高可靠性,但没有election过程,都是完全手工进行failover
我猜,chubby当时还没有启动,chubby论文发表于2006
master为什么不持久化chunk location?
其他的metadata是有redo log replication并持久化的,他们的变化,都是主动产生的,例如创建一个文件,增加一个chunk
而由于chunkserver随时可能crash,不受控制,因此通过heartbeat来计算并存放内存,通过heartbeat,master又可以修正chunkserver的一些错误,例如orphan chunk
Data flow为什么pipelined chain,而不并发?
为了避免产生网络瓶颈,同时为了更充分利用high latency links
通过ip地址,感知chunkserver直接的距离
Total Latency = (B/T) + (R*L)
2PC,避免了client(coordinator) crash问题,因为primary成为了coordinator,而它是有failover的
为什么搞个primary角色,而不让master做?
为了减轻master负担,所以搞了个二级调度:
跨chunk,master负责;chunk内部,primary负责
master如何revoke primary lease?
在lease expire后,master可能什么都不做
在lease expire前,master会sendto(primary)让它取消;如果sendto失败,那么只能等expire
为什么data flow和control flow分开?
如果不分开,那么所有的数据都是client->primary->secondary
分开后,比较轻量级的control flow必须走primary扩散;重量级的data flow可以根据物理拓扑进行优化
GFS vs Ceph
- 论文2003 vs 2006
- chunk(64MB) vs Object(4MB)
object size可配 - master vs mon(Paxos)
- chunkserver vs osd
- replication
- GFS
2PC, decouple data/control flow - Ceph
client <-> osd
- GFS
- Ceph通过PG+crunch提高了扩展性
GFS通过allocation table的方式 - GFS上直接跑MapReduce
计算向存储locality - Ceph更通用,latency更好
GFS通过lease提高扩展性,但遇到错误时只能等expire - 节点的变化
- GFS
chunkserver向master汇报,自动加入,完全不需要人工参与 - Ceph
需要通过ceph osd命令,手工执行
- GFS
- namespace
GFS是directory,Ceph是flat object id
2009 GFS回顾
GFS在使用了10年的过程中,发现了一些问题,对这些问题,有的是通过上层的应用来解决的,有的是修改GFS解决的
master ops压力
最开始的设计,考虑的是支撑几百TB,几百万个文件。但很快,到了几十PB,这对master有了压力
- master在recover的时候,也变慢
- master要维护的数据更多
- client与master的交互变慢
每次open,client都要请求master
MapReduce下,可能突然多出很多task,每个都需要open,master处理能力也就是每秒几千个请求
解决办法是在应用层垂直切分,弄多个cluster,应用通过静态的NameSpace找自己的master,同时提升单个master能力到数万ops
随着GFS的内部推广,越来越多的千奇百怪的上层应用连接进来
- 最开始是爬虫和索引系统
- 然后QA和research组用GFS来保存large data sets
- 再然后,就有50多个用户了
- 在此过程中GFS不断地调整以满足新use case
file-count问题
很早就发现了,例如:
- 前端机上要把log发到GFS保存以便MapReduce分析,前端机很多,每个log每天会logrotate,log的种类也越来越多
- gmail需要保存很多小文件
解决办法是把多个文件合并,绕开file-count问题,同时增加quota功能,限制file-count和storage space
长远的办法:在开发distributed multi-master系统,一个cluster可以有上百个master,每个master可以存1亿个文件,但
如果都是小文件,会有新的问题出现:more seek
再后来,建立在GFS之上的BigTable推出了,帮助GFS直接面对应用对小文件、多文件的需求,BigTable层给解决了,BigTable在使用GFS时,仍然是大文件、少文件
latency问题
GFS设计是只考虑吞吐率,而少考虑latency
error recovery慢
如果write一个文件,需要写到3个chunkserver,如果其中一个卡住了或crash,master会发觉(heartbeat),它会开新的一个chunkserver replica从其他chunkserver pull
master会把这个lock,以便新的client不能write(等恢复后再unlock)
而这个pullchunk操作,为了防止bandwidth burst,是有throttle的,限制在5-10MB/s,即一个64MB chunk,需要10s左右
等恢复到3个ok的时候再返回给client,client再继续write
在此过程中,client一直是block的
master failover慢
刚开始master failover完全靠人工,可能需要1h;后来增加了自动master failover,需要几分钟;再改进,可以在几秒钟内完成master自动切换
为吞吐量而设计的batch增加latency
解决办法
BigTable是无法忍受那么高的延时的,它的transaction log是最大的瓶颈,存储在GFS:
2个log(secondary log),一个慢,就切换到另外一个,这2个log任意时刻只有1个active,并且log entry里有sequence号,以便replay时防重
google使用这个request redundancy or timeout方法很广泛,为了解决search long tail latency,一样思路
Gmail是多机房部署的,一个卡了,切到另外机房
consistency
client一直push the write till it succeeds
但如果中途client crash了,会造成中间状态:不同client读同一个文件,可能发现文件长度不同
解决办法:使用append,offset统一由primary管理
但append由于没有reply保护机制,也有问题:
client write,primary分配一个offset,并call secondary,有的secondary收到有的没收到,此时primary crash
master会选另外一个作为primary,它可能会分配一个新的offset,造成该数据重复
如果为此再设计一套consensus,得不偿失
解决办法:single writer,让上层应用保证不并发写
Colossus
Colossus is specifically designed for BigTable, 没有GFS那么通用
In other words, it was built specifically for use with the new Caffeine search-indexing system, and though it may be used in some form with other Google services, it is not the sort of thing that is designed to span the entire Google infrastructure.
- automatically sharded metadata layer
- EC
- client driven replication
- metadata space has enabled availability analysis
BigTable
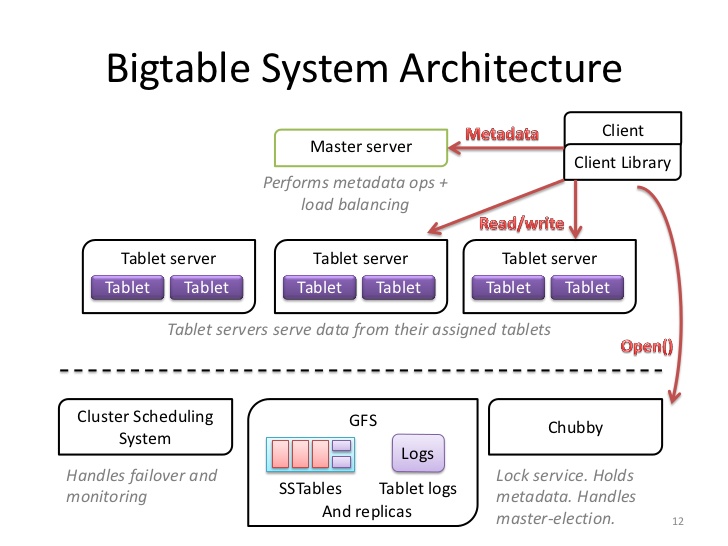
在有了GFS和Chubby后,Google就可以在上面搭建BigTable了,一个GFS的索引服务
但BigTable论文对很多细节都没有提到:SSTable的实现、tabletserver的HA,B+数的metadata table算法
为了管理巨大的table,按照row key做sharding,每个shard称为tablet(100-200MB,再大就split),每台机器存储100-1000个tablet
row key是一级索引,column是二级索引,版本号(timestamp)是三级索引
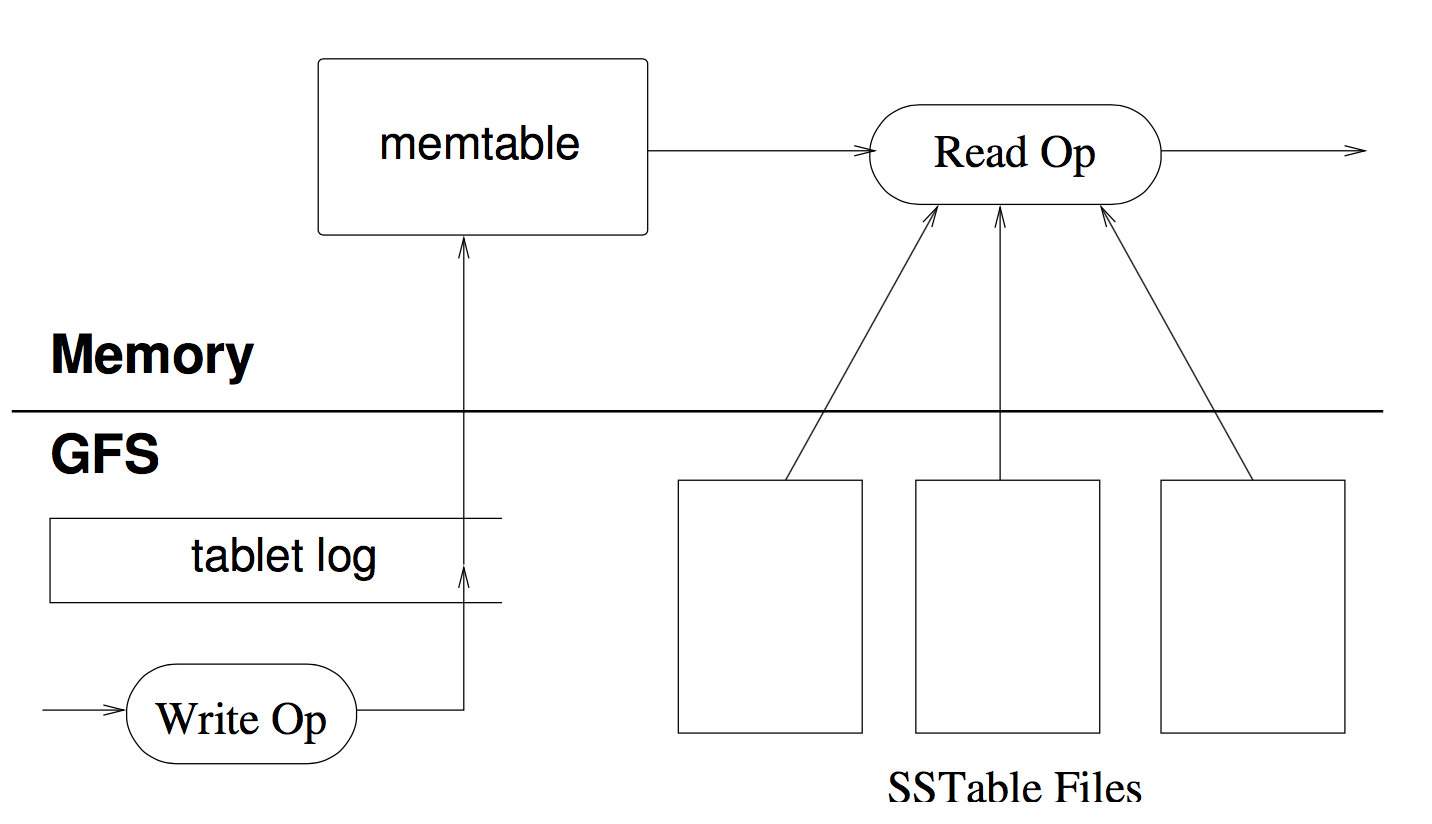
tabletserver没有任何的持久化数据,只是操作memtable,真正的数据存放在哪里只有GFS知道,那为什么需要master在chubby上分配tablet给tabletserver?
因为memtable是有状态的: level0
tabletserver的HA?
通过chubby ephemeral node,死了master会让别的server接管,通过GFS上的redo log恢复memtable
为了保证强一致性系统,同一时刻同一份数据只能一台tabletserver服务,tabletserver对每个tablet是没有备份的
当它crash,由于只需要排序很少的操作日志并且加载服务的tablet的索引,宕机恢复可以做到一分钟以内;在此期间,一部分rowkey不可用
split and migration?
在没有crash情况下,只需要修改metadata和从sstable加载索引数据,效率很高
与GFS的对应
- commit log
每台机器一个commit log文件,与GFS File一一对应 - sstable
HBase中Column Family的名称会被作为文件系统中的目录名称,每个CF存储成一个HDFS的HFile
据google工作过的人说:Column Families are stored in their own SSTable,应该是这样
sstable对应一个GFS File
sstable block=64KB,它与GFS的block相同
sstable block为了压缩和索引(binary search),GFS block为了checksum
Highlights
redo log合并
一台机器一个redo log,而不是一个tablet一个redo log(每个机器有100-1000个tablet),否则GFS受不了
group commit
带来的问题:恢复时麻烦了
如果一天机器crash了,它上面的tablets会被master分配到很多其他的tabletserver上
例如,分配到了100台新tabletserver,他们都会read redo log and filter,这样redo log被读了100次
解决办法:利用类似MapReduce机制,在recovery之前先给redo log排序
加速tablet迁移
|
|
SSTable由多个64KB的block组成
压缩以block为单位,虽然相比在整个SSTable上压缩比小(浪费空间),但对于随机读,可以只uncompress block而非整个SSTable
经验和教训
遇到了新的问题
- 发现了Chubby的bug
- network corruption
通过给RPC增加checksum解决 - delay adding features until clear how it will be used
刚开始想给API增加一个通用的事务机制,后来发现大部分人只需要单行事务 - 不仅监控server,也监控client
扩展了RPC,采样detailed trace of important actions - 设计和实现都要简单、明了
BigTable代码10万行C++
tabletserver的membership协议的设计,最初:master给tabletserver发lease
结果:在网络出问题时大大降低了可用性(master无法reach tabletserver就只能等expire)
改进:实现了更复杂的协议,也利用了Chubby里非常少见的特性
结果:大量时间在调试edge case,很多时间在调试Chubby的代码
最终:回到简单的设计,只依赖Chubby,而且只使用它通用的特性
Questions
按照rowkey来shard,那么可能造成hotspot问题,client端比较难控制
2009 BigTable回顾
部署了500+个BigTable集群,最大的机器:70+ PB data; sustained: 10M ops/sec; 30+ GB/s I/O
- Lots of work on scaling
- Improved performance isolation
- Improved protection against corruption
- Configure on per-table
- 异地机房复制: 增加了最终一致性模型
- Coprocessor
References
http://queue.acm.org/detail.cfm?id=1594206
http://google-file-system.wikispaces.asu.edu/
http://static.usenix.org/publications/login/2010-08/openpdfs/maltzahn.pdf
https://stephenholiday.com/notes/bigtable/