RADOS
Key ideas
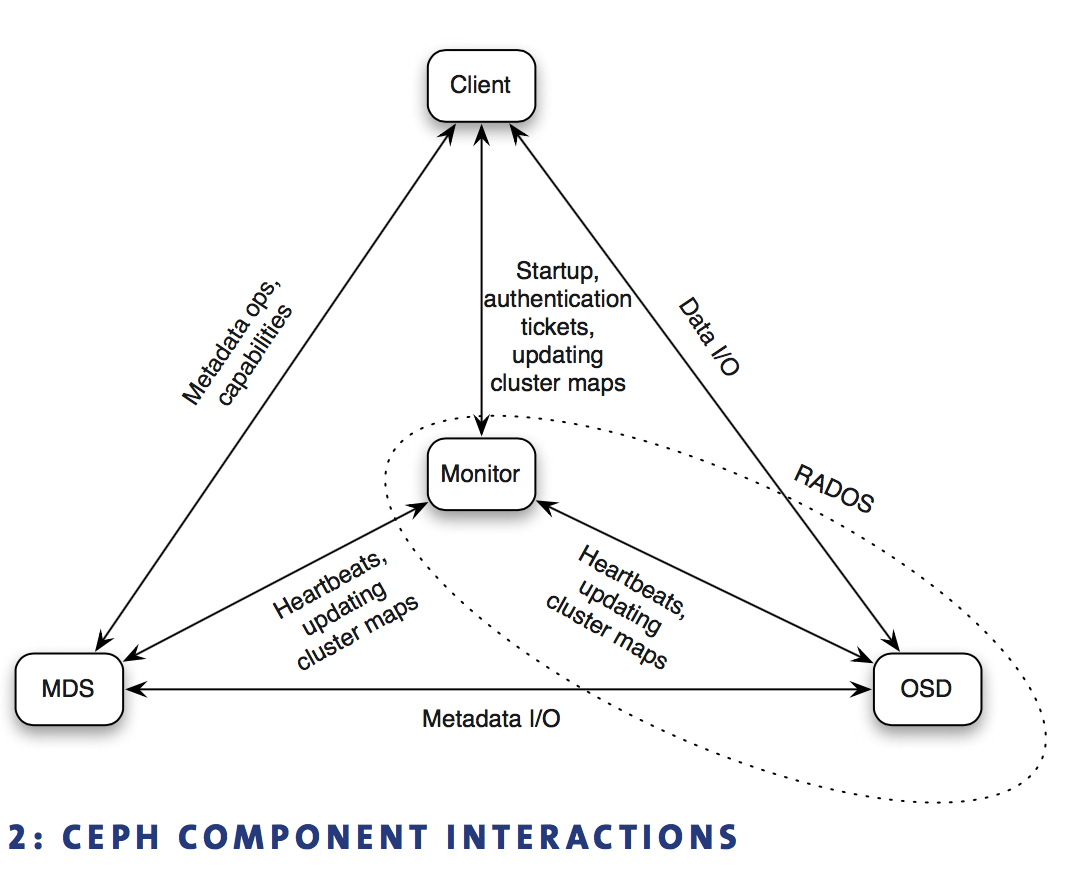
- 把传统文件系统架构分隔成client component and storage component
client负责更上层的抽象(file, block, object),storage负责底层object, disk - seperation of data and metadata
各管各的
Object
Object是最终落地存储文件的基本单位,可以类比fs block,默认4MB
如果一个文件 > object size,文件会被stripped,这个操作是client端完成的
It does not use a directory hierarchy or a tree structure for storage
It is stored in a flat-address space containing billions of objects without any complexity
Object组成
- key
- value
在fs里用一个文件存储 - metadata
可以存放在扩展的fs attr里
因此对底层文件系统是有要求的,ext4fs对extended attr数量限制的太少,可以用xfs
|
|
Lookup
|
|
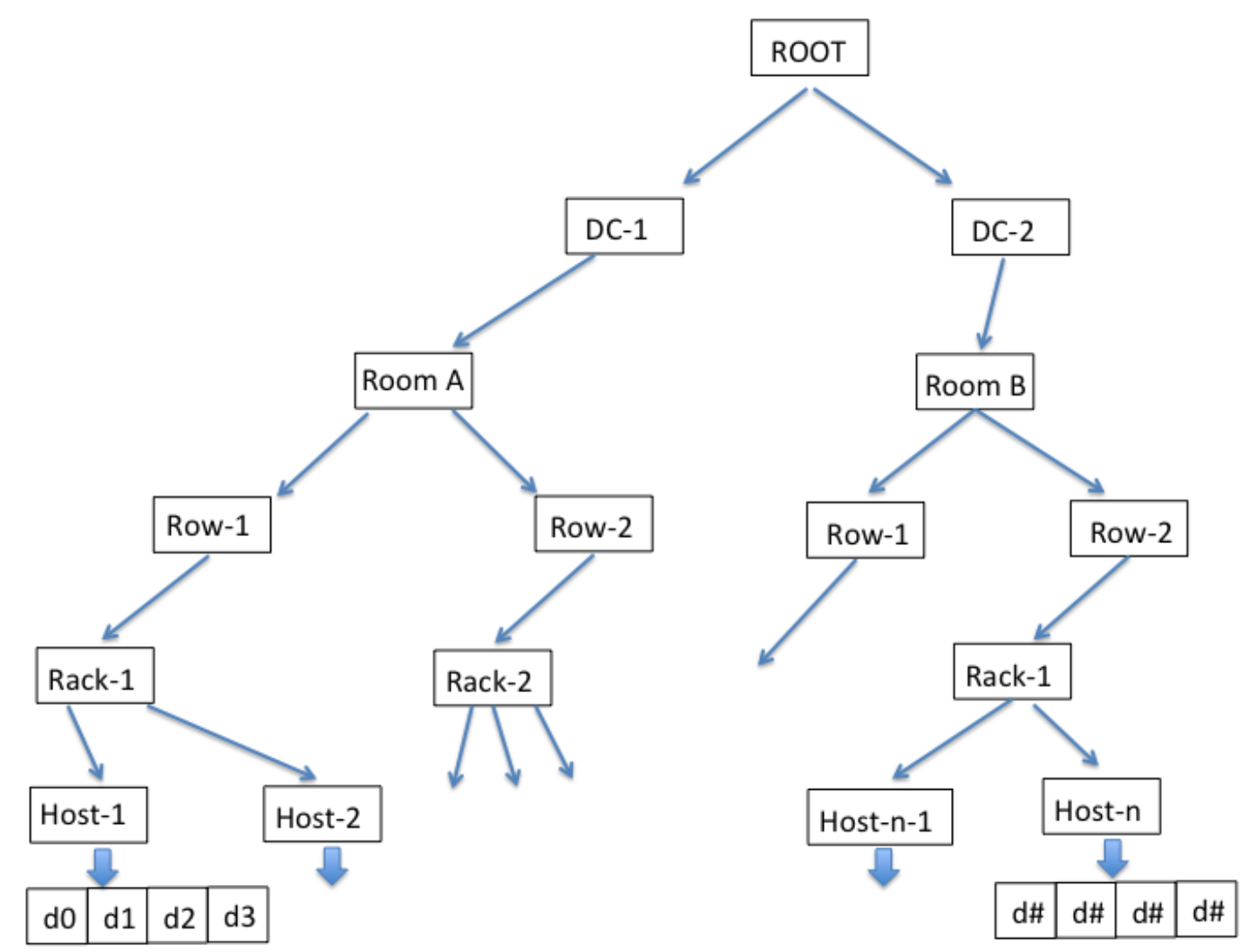
crush
一个hash算法,目标
- 数据均匀的分布到集群中
- 需要考虑各个OSD权重的不同(根据读写性能的差异,磁盘的容量的大小差异等设置不同的权重)
- 当有OSD损坏需要数据迁移时,数据的迁移量尽可能的少
有点像一致性哈希:failure, addition, removal of nodes result in near-minimal object migration
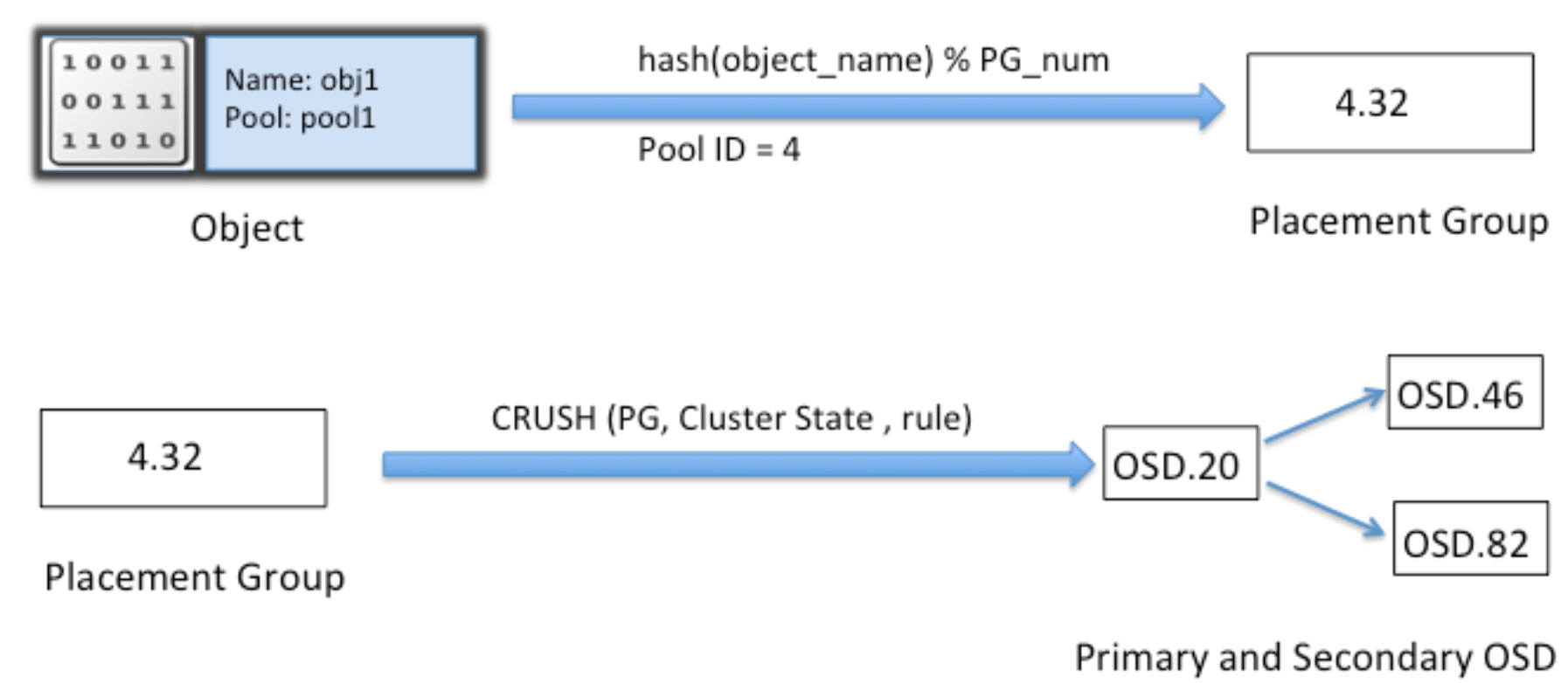
PG
PG(placement group)与Couchbase里的vbucket一样,codis里也类似,都是presharding技术
在object_id与osd中间增加一层pg,减少由于osd数量变化造成大量的数据迁移
PG使得文件的定位问题,变成了通过crush定位PG的问题,数量大大减少
例如,1万个osd,100亿个文件,30万个pg: 100亿 vs 30万
线上尽量不要更改PG的数量,PG的数量的变更将导致整个集群动起来(各个OSD之间copy数据),大量数据均衡期间读写性能下降严重
|
|
|
|
同一个PG内的osd通过heartbeat相互检查对方状态,大部分情况下不需要mon参与,减少了mon负担
mon
相当于Ceph的zookeeper
mon quorum负责整个Ceph cluster中所有OSD状态(cluster map),然后以增量、异步、lazy方式扩散到each OSD和client
mon被动接收osd的上报请求,作为reponse把cluster map返回,不主动push cluster map to osd
如果client和它要访问的PG内部各个OSD看到的cluster map不一致,则这几方会首先同步cluster map,然后即可正常访问
MON跟踪cluster状态:OSD, PG, CRUSH maps
同一个PG的osd除了向mon发送心跳外,还互相发心跳以及坚持pg数据replica是否正常
Replication
是primary-replica model, 强一致性,读和写只能向primary发起请求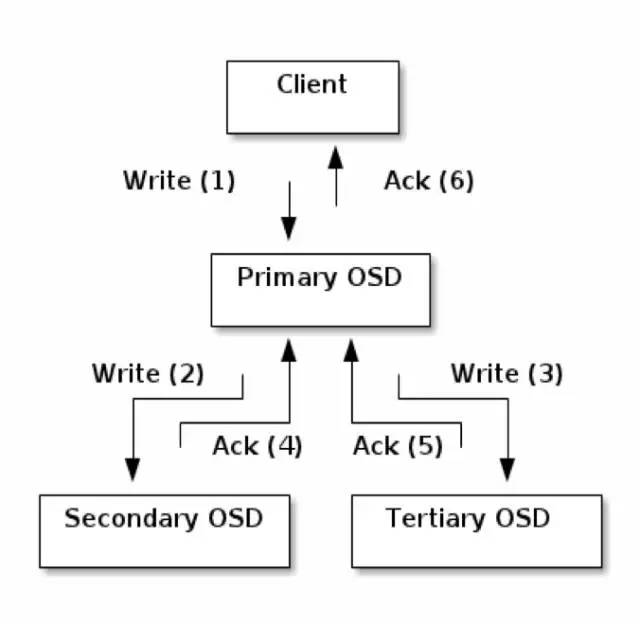
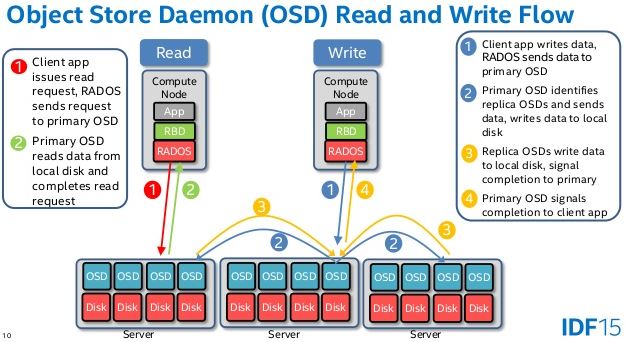
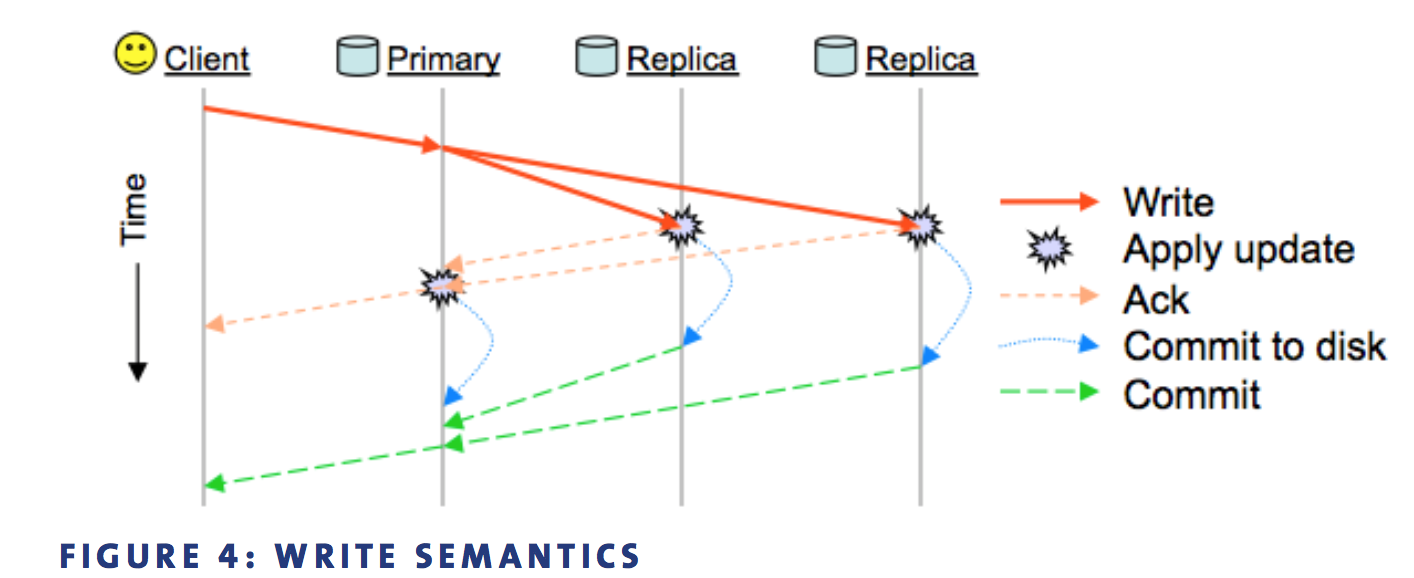
其中replicas在复制到buffer时就ack,如果某个replica复制时失败,进入degrade状态
2PC Write
|
|
scrub机制
read verify
Questions
consistency?
strongly consistent
Can Ceph replace facebook Haystack?
Haystack解决的实际上是metadata访问造成的IO问题,解决的方法是metadata完全内存,无IO
每个图片的read,需要NetApp进行3次IO: dir inode, file inode, file data
haystack每个图片read,需要1次IO,metadata保证在内存
在一个4TB的SATA盘存储20M个文件,每个inode如果需要500B,那么如果inode都存放内存,需要10GB内存
- 减少每个metadata的大小
去掉大部分不需要的数据,例如uid, gid, atime等
xfs里每个metadata占536字节,haystack每个图片需要10字节 - 减少metadata的总数量
多个图片(needle)合并进一个大文件(superblock)
用户上传一张图片,facebook会将其生成4种尺寸的图片,每种存储3份,因此写入量是用户上传量的12倍。
Posix规范里的metadata很多对图片服务器不需要,
Ceph解决了一个文件到分布式系统里的定位问题(crush(pg)),但osd并没有解决local store的问题: 如果一个osd上存储过多文件(例如10M),性能会下降明显
Why EC is slow?
Google Colossus采用的是(6,3)EC,存储overhead=(6+3)/6=150%
把数据分成6个data block+3个parity block,恢复任意一个数据块需要6个I/O
生成parity block和恢复数据时,需要进行额外的encode/decode,造成性能损失
Store small file, waste space?
object size是可以设置的
References
http://ceph.com/papers/weil-crush-sc06.pdf
http://ceph.com/papers/weil-rados-pdsw07.pdf
http://ceph.com/papers/weil-ceph-osdi06.pdf
http://www.xsky.com/tec/ceph72hours/
https://blogs.rdoproject.org/6427/ceph-and-swift-why-we-are-not-fighting
https://users.soe.ucsc.edu/~elm/Papers/sc04.pdf