Jim Gray, June 1985, Tandem Technical report 85.7
Terms
Reliability != Availability
- availability is doing the right thing within the specified response time
- Availability = MTBF/(MTBF + MTTR)
- 分布式系统下,整体的可用性=各个子系统可用性的乘积
- 模块化使得局部failure不会影响全部,冗余减少MTTR
- 磁盘的MTBF是1万小时,即1年;如果两张盘完全独立冗余,假设MTBR是24h,那么整体的MTBF是1000年
- reliability is not doing the wrong thing
Report
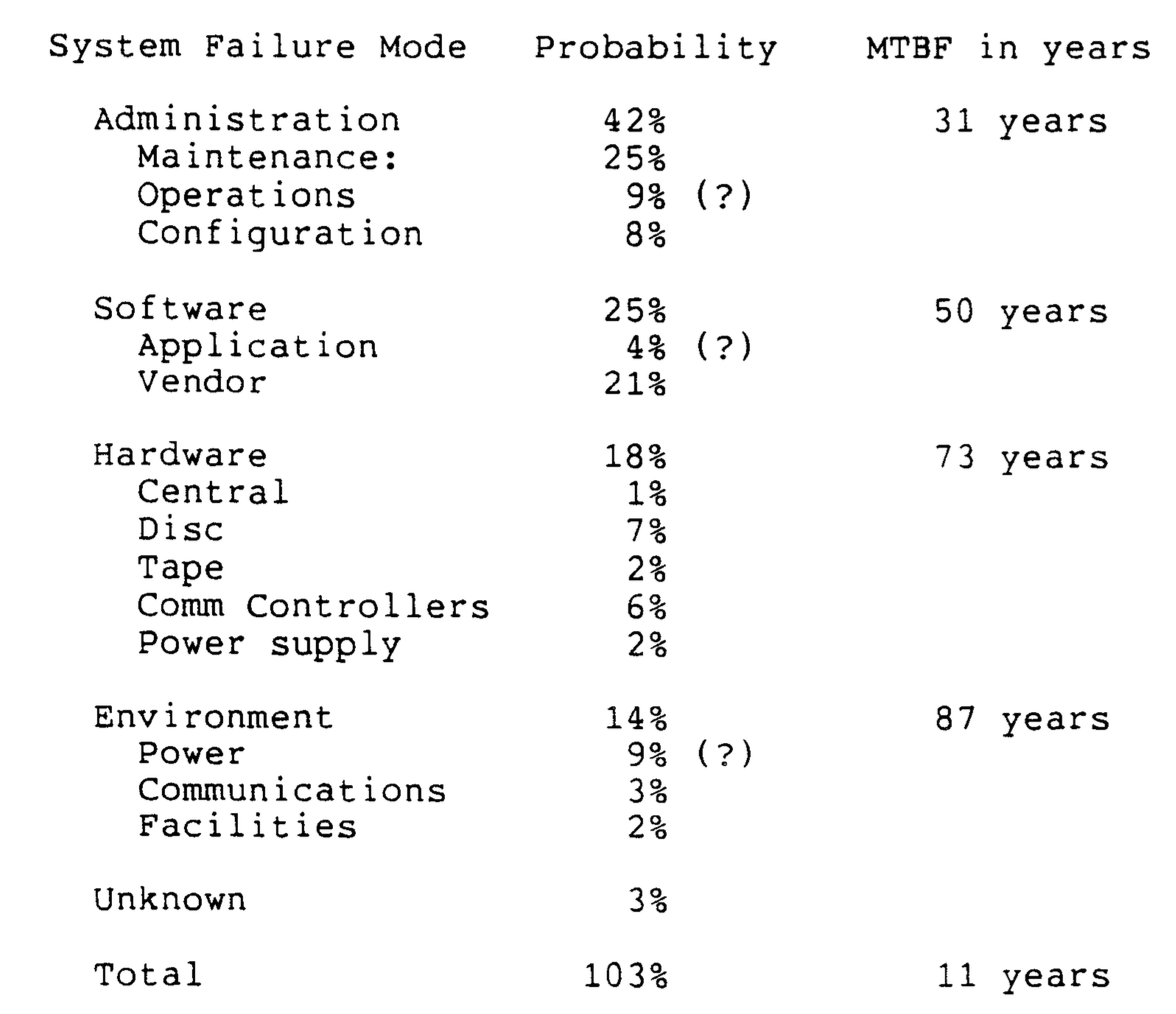
设计容错系统的方法
process pair
- Lockstep
一个执行失败,就启用另外一个
容忍了硬件故障,但没有解决Heisenbugs(难以重现的bug) - State Checkpointing
primary通过消息同步把请求发送给backup,如果primary挂了,切到backup
通过序列号来排重和发现消息丢失
实现起来比较困难 - Automatic Checkpointing
kernal自动管理checkpoint,而不是让上层应用管理
发送的消息很多 - Delta Checkpointing
发给backup的是logical updates,而不是physical updates
性能更好,消息更少,但也更难实现 - Persistence
失败的时候可能丢失状态
需要加入事务来提高可靠性
Fault-tolerent Communication
硬件,通过multiple data paths with independent failure modes
软件,引入session概念(类似tcp)
Fault-tolerent Storage
2份复制正好,3份不一定提高MTBF,因为其他失败因素会变为主导
分布式复制
把数据分片,会限制scope of failure