Background
Launched in 2014 for MySQL, and in 2016 for PostgreSQL.
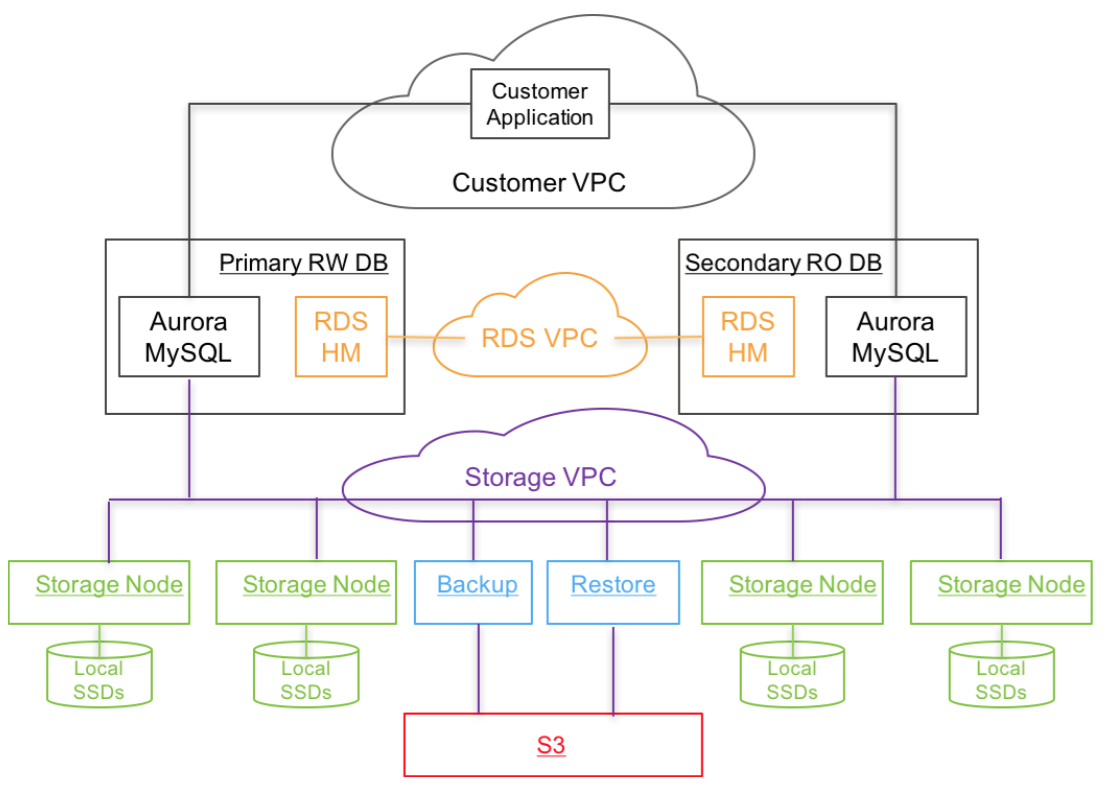
Aurora
基于shared disk的架构,storage共享来解决一致性问题,把计算节点与存储节点解耦,MySQL本身无状态,一写多读,S3做备份,本质上还是单机数据库
- 无法访问其binlog
- automatic storage scaling up to 64 TB, SSD
- 数据传输通过SSL(AES-256)
- 支持 100,000 writes/s, 500,000 read/s
- 费用
- 8 vCPU/61GB $1.16/h
- 16vCPU/122GB $2.32/h
- 32vCPU/244GB $4.62/h
每个月相当于2万多人民币
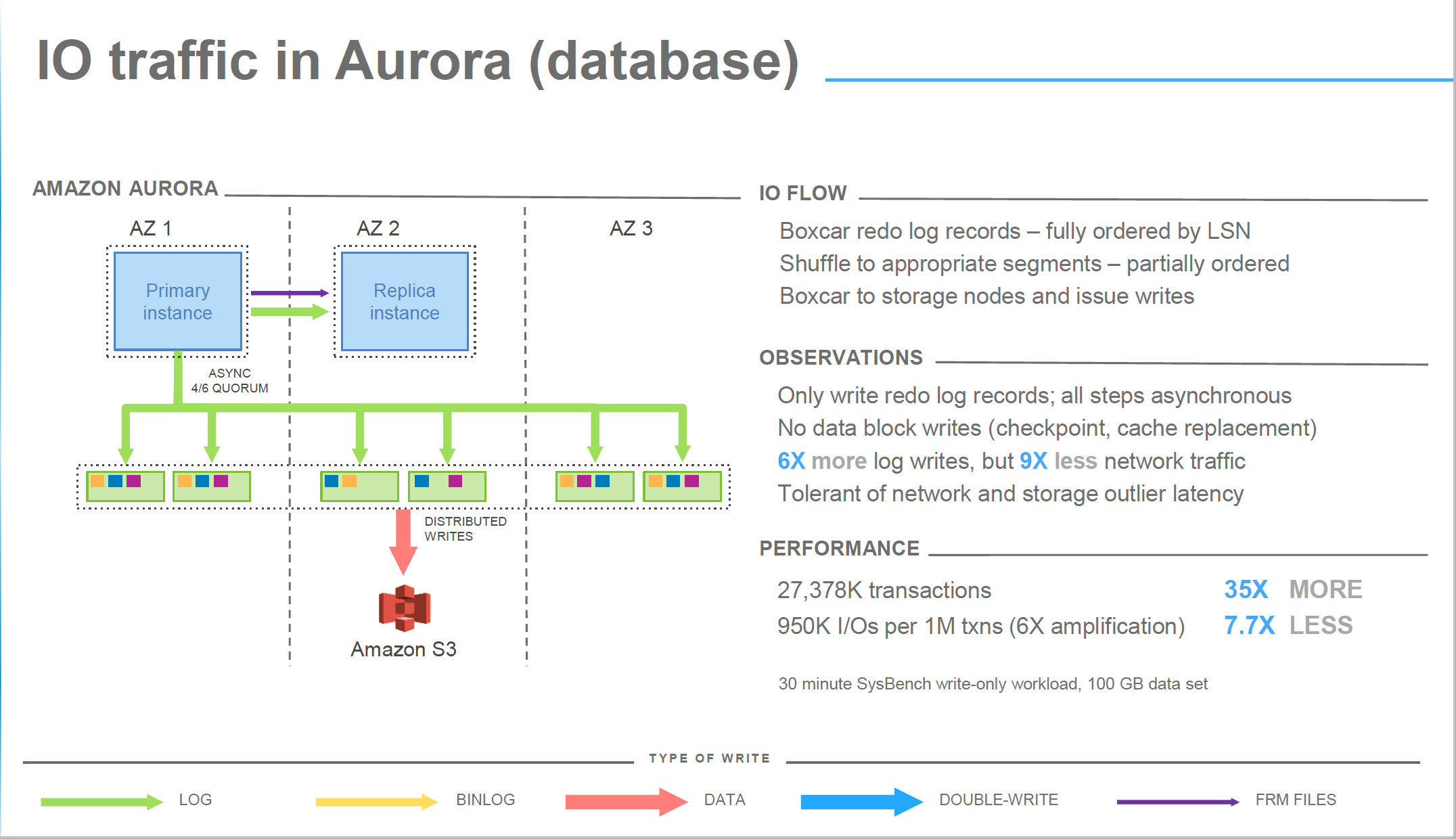
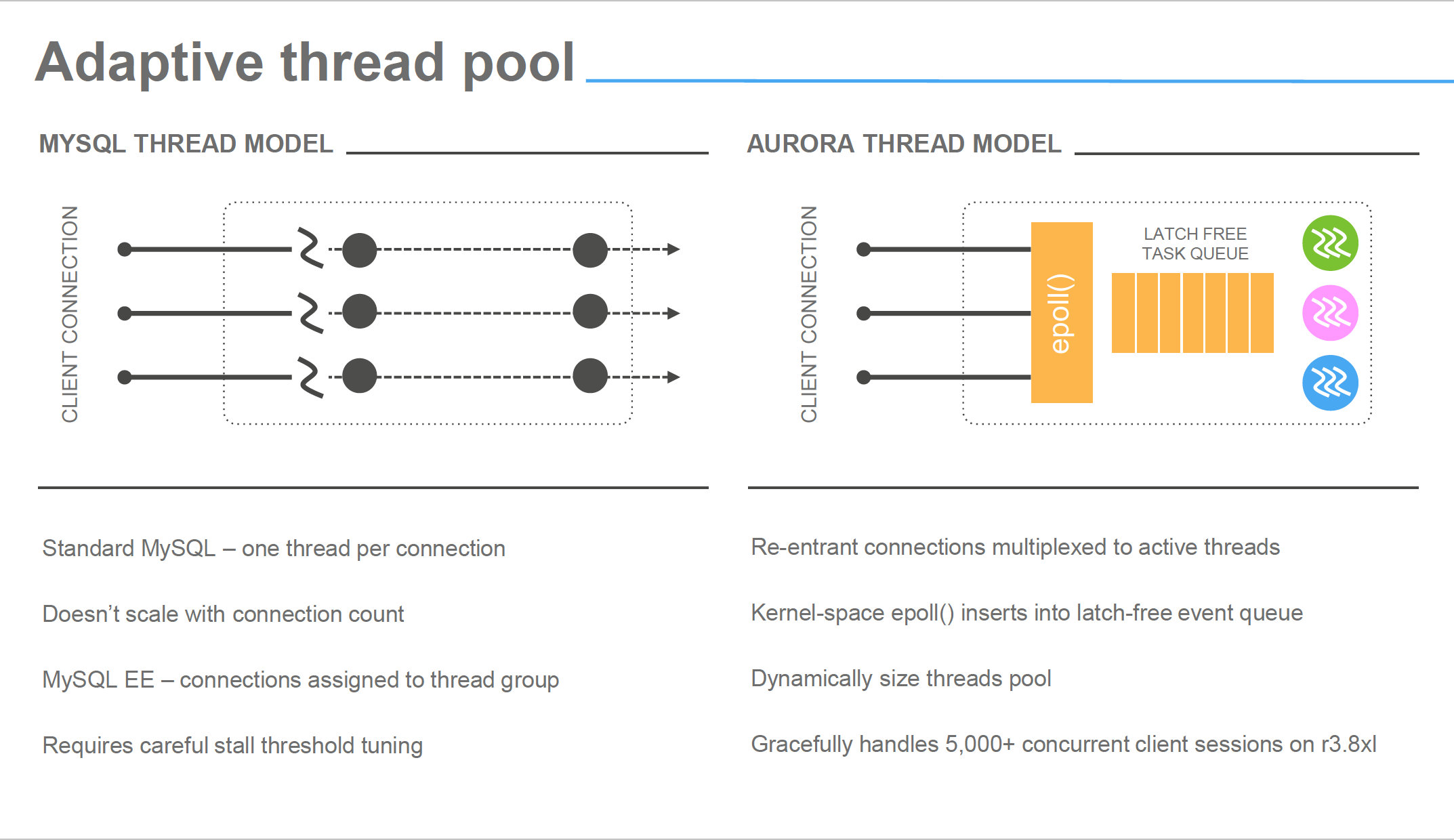
Architecture
Why not R(2)+W(2)>N(3) quorum?
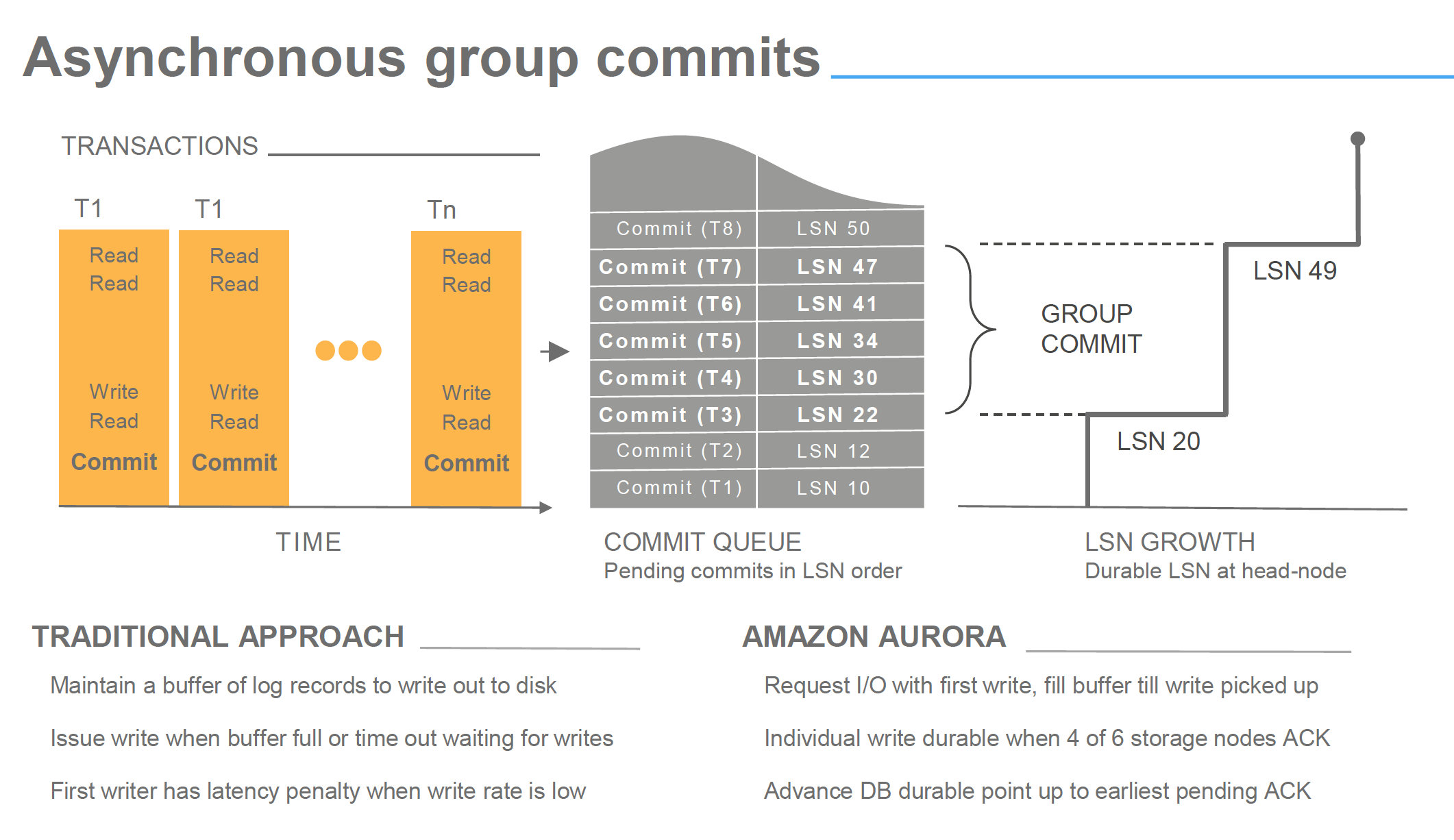
Aurora采用的是R(3)+W(4)>N(6) 3个AZ(但必须在同一个region),每个AZ上复制2份
它保证
- read与write集合是相交的
- W>N/2,防止写冲突
原因
- 写
- 2+2>3
只能容忍一个AZ crash - 3+4>6
只能容忍一个AZ crash
- 2+2>3
- 读
- 2+2>3
只能容忍一个AZ crash - 3+4>6
能容忍一个AZ crash,此外允许另外一个node crash,即AZ+1
为什么这个重要?因为data durability是指写进去的数据能读出来,它提高了durability
- 2+2>3
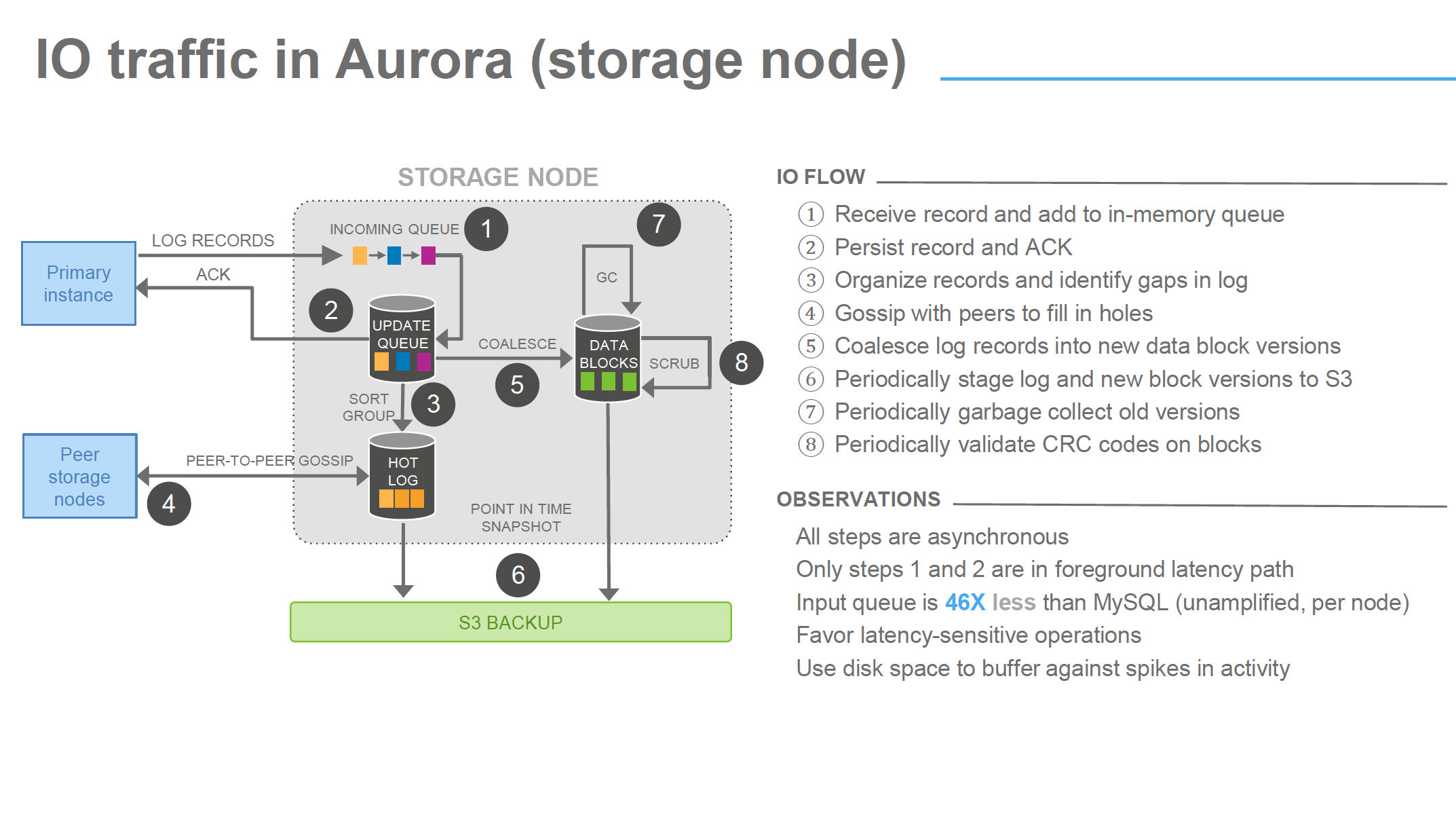
Why segmented storage
如果一个AZ crash了,就会破坏write quorum,降低availability,为了提高availability(99.99%),他们采用的方法是降低MTTR
类似ES,数据存储(ibdata)被segment化,each 10GB,total max 64TB,每个segment复制6份(3 AZ),10GB是为了能控制MTTR在10s
segment就成为了independent background noise failure and repair,后台有应用不停地检查、修复segment错误,如果不segment,那么修复成本很高
同时,是考虑到底层存储机制,做线性扩容方便
Scale
- scale write
只能把master机器升级到更高的ec2: scale up, not scale out - scale read
add more read replicas
References
http://www.allthingsdistributed.com/files/p1041-verbitski.pdf
https://www.percona.com/blog/2016/05/26/aws-aurora-benchmarking-part-2/
http://www.tusacentral.net/joomla/index.php/mysql-blogs/175-aws-aurora-benchmarking-blast-or-splash.html