Overview

Controller
负责
- leadership change of a partition
each partition leader can independently update ISR
- new topics; deleted topics
- replica re-assignment
曾经的设计是没有controller,每个broker要决策时都通过zk,加入controller坏处就是要实现controller failover
1 2 3 4 5 6 7
| class KafkaController { partitionStateMachine PartitionStateMachine replicaStateMachine ReplicaStateMachine // controller选举,并LeaderChangeListener controllerElector ZookeeperLeaderElector }
|
ControllerContext
一个全局变量。在选举为controller时,一次性从zk里读入所有状态信息KafkaController.initializeControllerContext
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| class ControllerContext { epoch, epochZkVersion, correlationId controllerChannelManager // 维护controller与每个broker之间的socket conn // 初始化时从/brokers/ids里取得的,并在BrokerChangeListener里修改 liveBrokersUnderlying: Set[Broker] // 初始化时从/brokers/topics里取得的,并在TopicChangeListener里修改 allTopics: Set[String] // 初始化时从/brokers/topics/$topic里一一取得,并在如下情况下修改 // - assignReplicasToPartitions.assignReplicasToPartitions // - updateAssignedReplicasForPartition // - TopicChangeListener // - ReplicaStateMachine.handleStateChange partitionReplicaAssignment: mutable.Map[TopicAndPartition, Seq[Int]] // AR // 初始化时从/brokers/topics/$topic/$partitionID/state一一取得,如下情况下修改 // - PartitionStateMachine.initializeLeaderAndIsrForPartition // - PartitionStateMachine.electLeaderForPartition partitionLeadershipInfo: mutable.Map[TopicAndPartition, LeaderIsrAndControllerEpoch] }
|
ControllerChannelManager
controller为每个broker建立一个socket(BlockingChannel)连接和一个thread用于从内存batch取request进行逐条socket send/receive
e,g. 1个8节点的机器,controller上为这部分工作,需要建立(7个线程 + 7个socket conn)
与每个broker的连接是并发的,互不干扰;对于某一个broker,请求是完全串行的
config
- controller.socket.timeout.ms
default 30s, socket connect/io timeout
broker shutdown/startup/crash?
zk.watch(“/brokers/ids”), BrokerChangeListener会调用ControllerChannelManager.addBroker/removeBroker
conn broken/timeout?
如果socket send/receive失败,那么自动重连重发,backoff=300ms,死循环
但如果broker长时间无法reach,它会触发zk.watch(“/brokers/ids”),removeBroker,死循环退出
ControllerBrokerRequestBatch
controller -> broker,这里的圣旨请求有3种,都满足幂等性
- LeaderAndIsrRequest
replicaManager.becomeLeaderOrFollower
- UpdateMetadataRequest
replicaManager.maybeUpdateMetadataCache
- StopReplicaRequest
删除topic
onBrokerStartup
由BrokerChangeListener触发
1 2 3 4 5 6 7
| sendUpdateMetadataRequest(newBrokers) // 告诉它它上面的所有partitions replicaStateMachine.handleStateChanges(allReplicasOnNewBrokers, OnlineReplica) // 让所有的NewPartition/OfflinePartition进行leader election partitionStateMachine.triggerOnlinePartitionStateChange()
|
onBrokerFailure
找出受影响的状态,并触发partitionStateMachine、replicaStateMachine的状态切换
StateMachine
只有controller那台机器的state machine才会启动
terms
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| Replica { broker_id int partition Partition // a Replica belongs to a Partition log Log hw, leo long isLeader bool } Partition { topic string partition_id int leader Replica ISR Set[Replica] AR Set[Replica] // assigned replicas zkVersion long // for CAS }
|
PartitionStateMachine
每个partition的状态,负责分配、选举partion的leader
1 2 3 4 5 6 7 8 9 10 11
| class PartitionStateMachine { // - NonExistentPartition // - NewPartition // - OnlinePartition // - OfflinePartition partitionState: mutable.Map[TopicAndPartition, PartitionState] = mutable.Map.empty topicChangeListener // childChanges("/brokers/topics") addPartitionsListener // all.dataChanges("/brokers/topics/$topic") deleteTopicsListener // childChanges("/admin/delete_topics") }
|
- PartitionLeaderSelector.selectLeader
- OfflinePartitionLeaderSelector
- ReassignedPartitionLeaderSelector
- PreferredReplicaPartitionLeaderSelector
- ControlledShutdownLeaderSelector
ReplicaStateMachine
每个partition在assigned replic(AR)上的状态,track每个broker的存活
1 2 3 4 5 6 7 8 9 10
| class ReplicaStateMachine { replicaState: mutable.Map[PartitionAndReplica, ReplicaState] = mutable.Map.empty brokerRequestBatch = new ControllerBrokerRequestBatch // 只有controller关心每个broker的存活,broker自己是不关心的 // 而且broker die只有2种标准,不会因为conn broken认为broker死 // 1. broker id ephemeral znode deleted // 2. broker controlled shutdown brokerChangeListener // childChanges("/brokers/ids") }
|
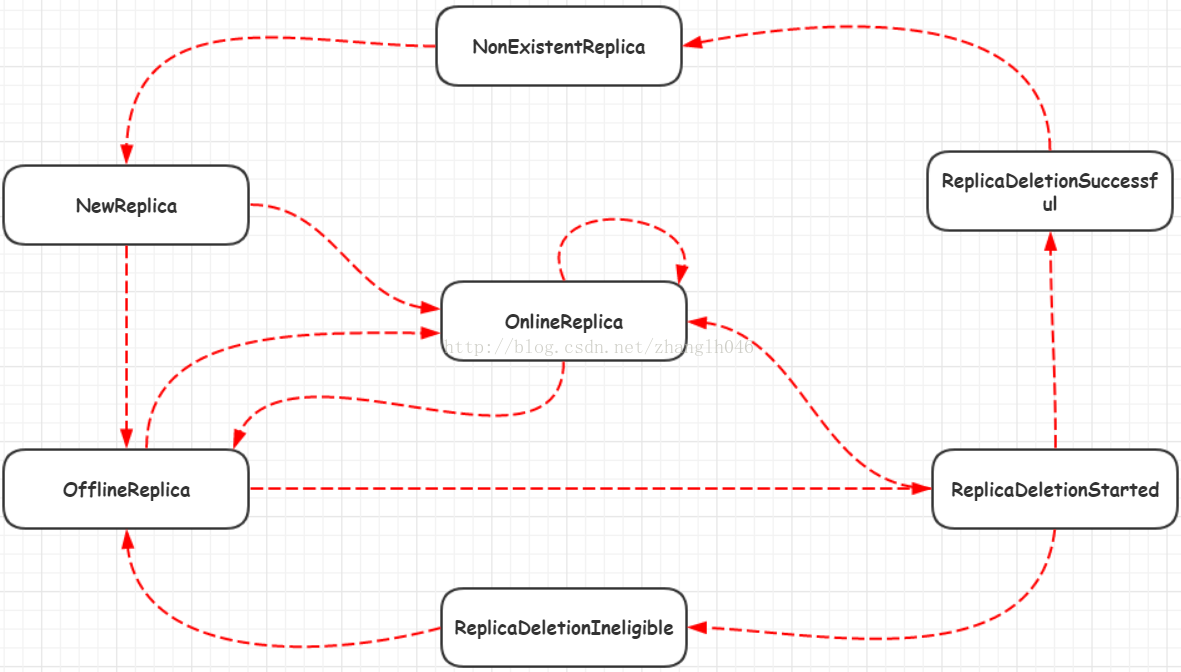
startup
对所有replica,如果其对应的broker活,那么就置为OnlineReplica,否则ReplicaDeletionIneligible
state transition
- 校验当前状态与目标状态
- 维护内存replicaState
- 必要时通过brokerRequestBatch广播给所有broker
Failover
broker failover
每个broker有KafkaHealthcheck,它向/brokers/ids/$id这个ephemeral znode写数据,session expire就会重写,其中timestamp置为当前时间
1
| {"jmx_port":-1,"timestamp":"1460677527837","host":"10.1.1.1","version":1,"port":9002}
|
controller的BrokerChangeListener监视所有broker的存活
参考 onBrokerStartup, onBrokerFailure
leader failover
一个partition的leader broker crash了,controlle选举出新的leader后,该new leader的LEO会成为新的HW
leader负责维护/propogate HW,以及每个follower的LEO
存在一个partition多Leader脑裂
1 2 3 4 5
| partition0 broker(A, B, C),A是leader A GC很久,crontroller认为A死,让B成为leader,写zk ISR znode,正在此时A活了但还没有收到controller发来的RPC,此时A、B都是leader 如果client1连接A,clientB连接B,他们都发消息? A活过来的时候,A认为它的ISR=(A,B,C),clientA发的消息commit条件是A,B,C都ack by fetch request才可以,但B在promoted to leader后会先stop fetching from previous leader。 因此,A只有shrink ISR后才可能commit消息,但shrink时它会写zk,通过CAS失败,此时A意识到它已经不是leader
|
controller failover
controller session expire example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
| broker1,是controller 在sessionTimeout*2/3=4s内还没有收到response,就会try next zk server zk connected,发现session(0x35c1876461ec9d3)已经expire了 触发KafkaController.SessionExpirationListener { onControllerResignation() brokerState设置为RunningAsBroker // 之前是RunningAsController controllerElector.elect { switch write("/controller") { case ok: onBecomingLeader { // 1 successfully elected as leader // Broker 1 starting become controller state transition controllerEpoch.increment() register listeners replicaStateMachine.startup() partitionStateMachine.startup() brokerState = RunningAsController sendUpdateMetadataRequest(to all live brokers) } case ZkNodeExistsException: read("/controller") and get leaderID } } } broker0: ZookeeperLeaderElector.LeaderChangeListener被触发,它watch("/controller") { elect }
|
Misc
- ReplicationUtils.updateLeaderAndIsr
References
https://issues.apache.org/jira/browse/KAFKA-1460
https://cwiki.apache.org/confluence/display/KAFKA/kafka+Detailed+Replication+Design+V3
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Improvement+Proposals