config
Topology config
- TOPOLOGY_WORKERS
- 整个topology在所有节点上的java进程总数
- 例如,设置成25,parallelism=150,那么每个worker进程会创建150/25=6个线程执行task
- TOPOLOGY_ACKER_EXECUTORS = 20
- 不设或者为null,it=TOPOLOGY_WORKERS,即one acker task per worker
- 设置为0,表示turn off ack/reliability
TOPOLOGY_MAX_SPOUT_PENDING = 5000
123(defn executor-max-spout-pending [storm-conf num-tasks](let [p (storm-conf TOPOLOGY-MAX-SPOUT-PENDING)](if p (* p num-tasks))))- max in-flight(not ack or fail) spout tuples on a single spout task at once
- 如果不指定,默认是1
TOPOLOGY_BACKPRESSURE_ENABLE = false
- TOPOLOGY_MESSAGE_TIMEOUT_SECS
30s by default
KafkaSpout config
|
|
emit/ack/fail flow
|
|
Bolt ack
KafkaSpout产生的每个tuple,Bolt必须进行ack,否则30s后KafkaSpout会认为emitted tuple tree not fully processed,进行重发123456class MyBolt { public void execute(Tuple tuple) { _collector.emit(new Values(foo, bar)) _collector.ack(tuple) }}
OOM
如果消息处理一直不ack,累计的unacked msg越来越多,会不会OOM?
NO
KafkaSpout只保留offset,不会保存每条emitted but no ack/fail msg
spout throttle
1.0.0之前,只能用TOPOLOGY_MAX_SPOUT_PENDING控制
但这个参数很难控制,它有一些与其他参数配合使用才能生效的机制,而且如果使用Trident语义又完全不同
1.0.0之后,可以通过backpressure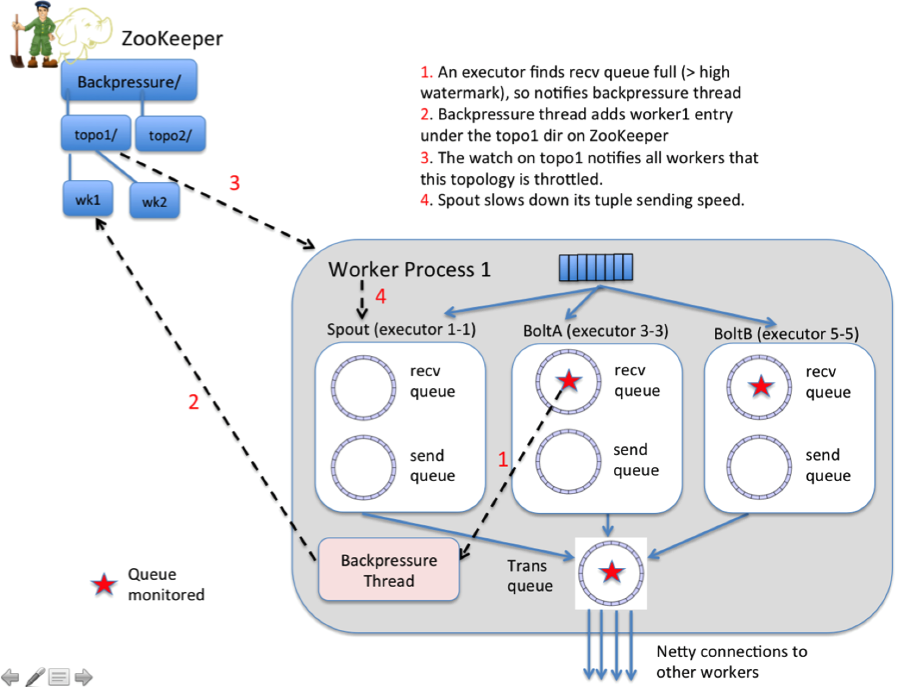
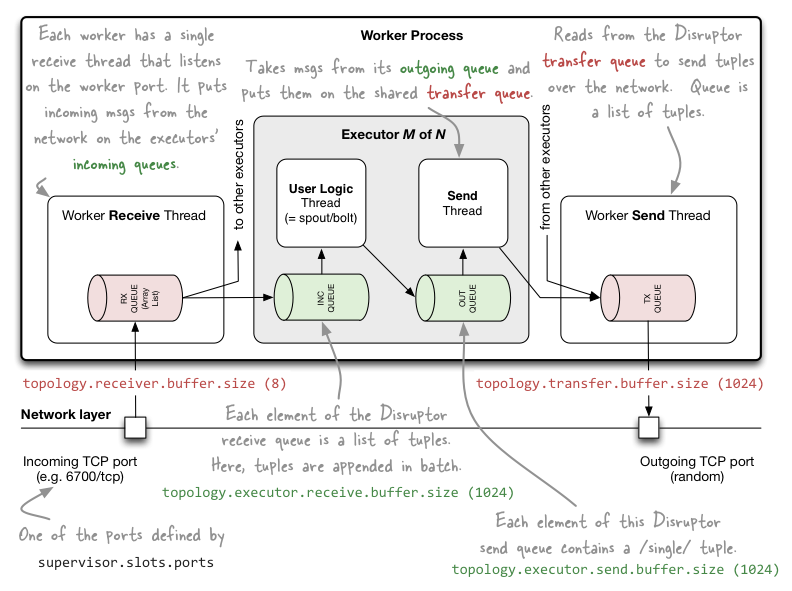
Storm messaging
- intra-worker
Disruptor - inter-worker
0MQ/Netty
References
http://www.michael-noll.com/blog/2013/06/21/understanding-storm-internal-message-buffers/
http://jobs.one2team.com/apache-storms/
http://woodding2008.iteye.com/blog/2335673