简介
GR是个mysql插件,通过原子广播协议、乐观事务冲突检测实现了高可用的多master集群
每个master都有全量数据,client side load balance write workload或者使用ProxySQL
读事务都是本地执行的
有2种模式
- 单主,自动选主
- 多主,active active master
与PXC是完全的竞争产品
Requirements and Limitations
- InnoDB engine only, rollback uncommitted changes
- turn on binlog RBR
- GTID enabled
- each table MUST have a primary key或者not null unique key
- no concurrent DDL
- 至少3台master,至多9台,不需要slave
- auto_increment字段通过offset把各个master隔离开,避免冲突
- cascading foreign key not supported
- 只是校验write set,serializable isolation NOT supported
- 存在stale read问题,如果write/read不在一台member
- savepoints可能有问题
Performance
http://mysqlhighavailability.com/an-overview-of-the-group-replication-performance/
80% throughput of a standalone MySQL server
Internals
XCOM
eXtended COMmunications,一个Paxos系统
- 确保消息在所有member上相同顺序分发
- 动态成员,成员失效检测
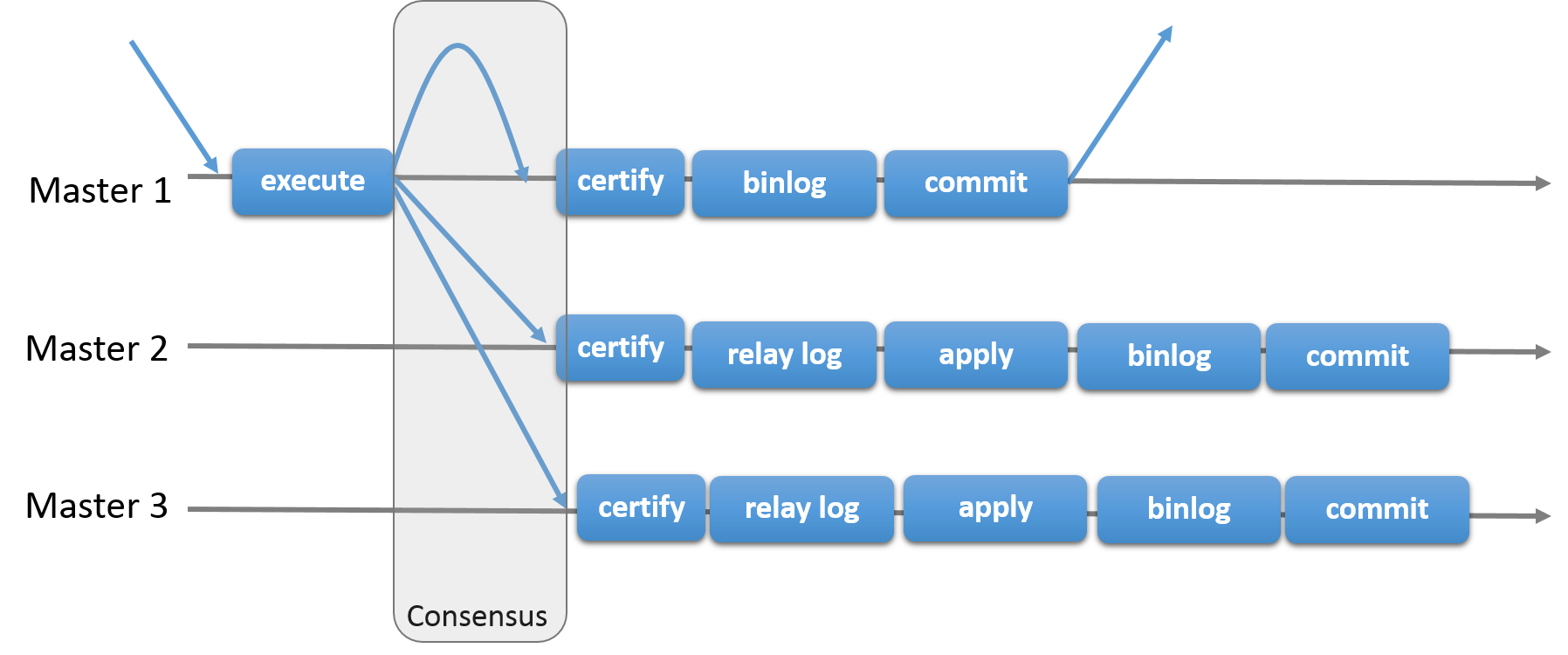
事务的Update操作都在一个成员上执行,在Commit时把write-set以total order发送消息给每个成员;
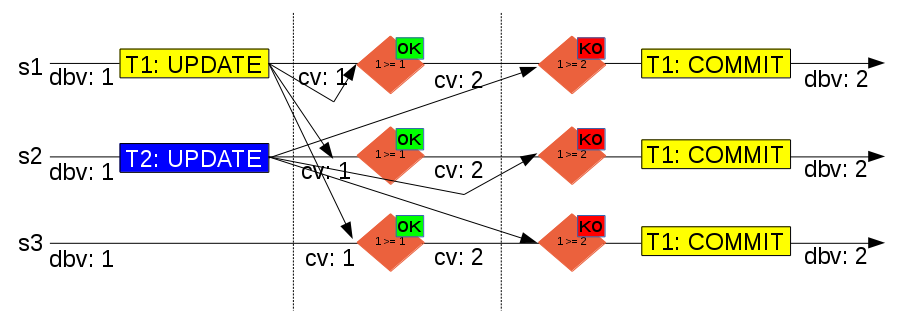
每个成员上的certification进程检查事务冲突(first commit wins),完成最终提交或回滚
Commit时的Paxos有2个作用
- certification,检测事务冲突
- propagate
Group Replication ensures that a transaction only commits after a majority of the members in a group have received it
and agreed on the relative order between all transactions that were sent concurrently.
与multi-paxos不同,XCOM是multi-leader/multi-proposer:每个member都是leader of its own slots
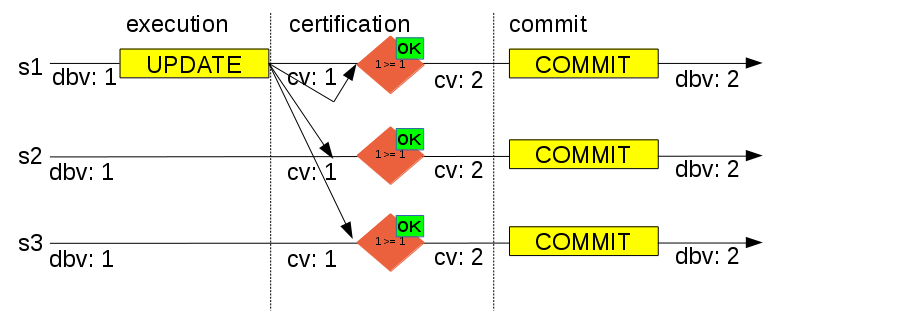
Certification
group_replication_group_name就是GTID里的UUID
GTID就是database version
mysql> select @@global.gtid_executed
transaction write set: [{updated_row_pk: GTID_EXECUTED}, {updated_row_pk: GTID_EXECUTED}, …]
GTID是由certification模块负责的,由它来负责GTID GNO的increment
所有member会定期交换GTID_EXECUTED,所有member已经committed事务的交集:Stable Set.
Transaction
Distributed Recovery
向group增加新成员的过程: 获取missing data,同时cache正在发生的新事务,最后catch up
|
|
这个过程与mysql在线alter table设计原理类似
binlog view change markers
group里member变化,会产生一种新的binlog event: view change log event.
view id就是一种logicl clock,在member变化时inrement
epoch在第一个加入group的member生成,作用是为了解决all members crash问题: avoid dup counter
certification based replication
通过group communication和total order transaction实现synchronous replication
事务在单节点乐观运行,在commit时,通过广播和冲突检测实现全局数据一致性
它需要
- transactional database来rollback uncommitted changes
- primary keys to generate broadcast write-set
- atomic changes
- global ordering replication events
Config
|
|
FAQ
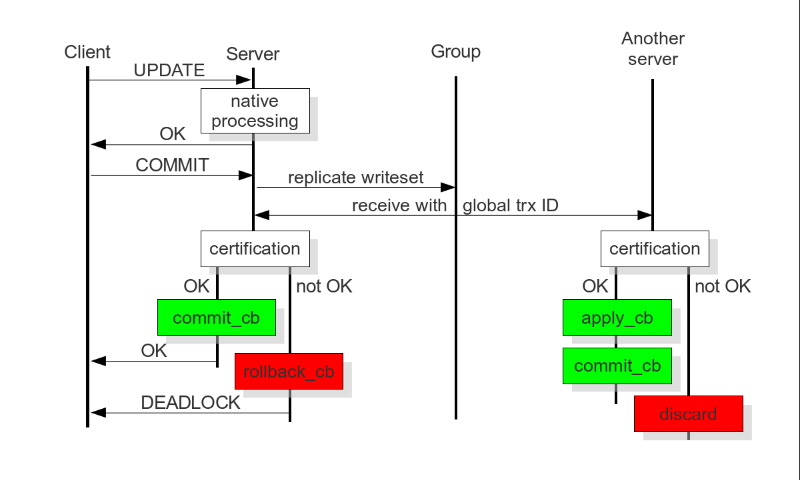
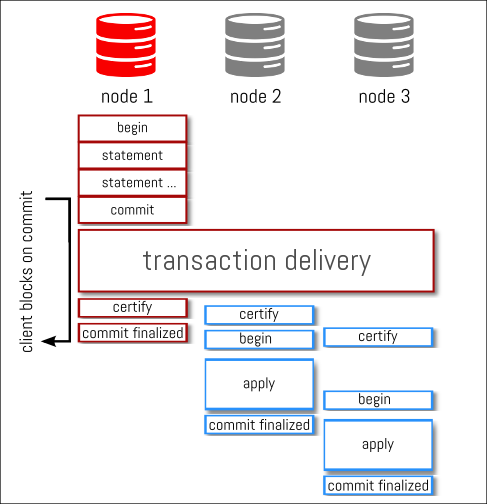
GR是同步还是异步?
replication分为5步
GR下,只有3是同步的: 把write set广播并得到majority certify confirm
广播时发送消息是同步的,但apply write set还是异步的:
References
http://lefred.be/content/mysql-group-replication-about-ack-from-majority/
http://lefred.be/content/mysql-group-replication-synchronous-or-asynchronous-replication/
http://lefred.be/content/galera-replication-demystified-how-does-it-work/
http://www.tocker.ca/2014/12/30/an-easy-way-to-describe-mysqls-binary-log-group-commit.html
http://mysqlhighavailability.com/tag/mysql-group-replication/
http://mysqlhighavailability.com/mysql-group-replication-transaction-life-cycle-explained/